风云善变 江湖易老----致敬Zeppelin

Zeppelin
zeppelin 是一个AP的高速分布式高可用kv存储平台。目前稳定运行2年有余,由于架构变动,zeppelin不再适合现有的需求,决定洒泪放弃zeppelin。正所谓风云善变,江湖易老,仅以此文致敬zeppelin祭奠我与此片江湖的成长历程。
0,Overview
Zeppelin简介:
1,提供Set Get Delete Mset Mget Inc等接口
2, 支持TTL
3,支持hashtag 将同样的tag hash到一个partition中
总体来看zeppelin(zp)有两个组件,meta server负责元信息的管理,采用的是有中心的元信息管理方式。node server负责数据的存储同步。
meta的信息主要包括table信息,node信息(up/down, binlog offset)等等。为了实现meta信息的一致性,每个meta server 都拥有一个floyd(raft 实现) 实例用于同步和持久化meta信息。
node节点中最小同步单位是partition, 为解决单点问题,实现高可用,每个主partition 还有额外两个副本,主从副本同步通过binlog来实现。
Zp客户端是智能客户端,client请求流程如下
1,从meta上拉取meta信息
2,本地计算key对应的partition
3,从meta信息查询partition对应的ip地址
4, 向对应ip发送请求
这样的设计可以减少meta sesrver转发的压力,流量不需要meta转发,而是直接打到对应的node server上。
总体来看zeppelin的服务端分为两个部分node_server 和meta_server。本文会分别介绍这两个组件。
1,Node Server
1.1 Data Distribution
zeppelin采用分片的数据分布模型。市面上的数据分布方法有很多, Dynamo的论文里面做了一些总结,相比于哈希,一致性哈希等模型,分片哈希取模 模型兼顾了故障与隔离,节点异构,负载均衡,迁移扩容等因素。将数据空间分为固定大小的partition(for example1024)。为了容灾解决单点的问题,每一个partition有两个副本(slave)。原则上主partition(master partition)和从partition (slave partition)分布在不同的机器(physical machine)上,master partition故障之后可以自动切主,实现比较快的故障恢复。
Pros:
1,扩容迁移以partition为单位,比较方便,
2,考虑了节点间的异构
3,负载比较均衡
4,故障域可配置
Cons:
1,不能动态添加partition
zp的partition hash modulo模型相比于mangodb range
mangodb 的range 模型中meta信息记录了每个key对应到相应的chunk,chunk的分裂就是修改meta的过程
zp的哈希取模的分片模型中 meta记录了table的分片个数,相对于mangodb的meta相对轻量级很多,但是由于分片是哈希的原因,造成partition不能分裂。
详细的分析: range VS hash
1.2 Thread Model
红色
Dispatch Thread Worker Thread 负责客户端请求的处理。
[网络层] Dispatch Thread 在创建链接之后,将创建conn的信息写入管道,相应的workerthread 读取管道内容将conn加入自己的epoll,监听EPOLLIN 事件。
WorkerThread 收到来自client的PB 数据包,解包之后写入db.
蓝色
Partition的role 如果是master,BinlogSenderThread 负责从binlog文件读取binlog 同步给slave partitions。
Partition的role 如果是slave, BinlogReceiver Thread负责接收master partition同步过来的binlog。为了提供跟master partition 一样的处理效率Binlog Thread将binlog 分发到worker thread进行处理。
TrySyncTread 负责slave partition向master partition 发送请求同步信息。
绿色
HeartbeatThread 每过kPingInterval 秒向meta server报告自己的partition 信息包括epoch信息 binlogoffset信息。epoch信息代表meta信息的版本,任何对meta信息的修改epoch都会自增。如果拿到metaserver 回复的信息 epoch信息不一致,就会通知 meta Cmd thread, 从metaserver pull meta 信息,本地做相应更新操作。
黄色
BgSave and DbSync thread 主要用作全量同步的时候做Dbdump操作和全量同步(rsync)。
BinlogPurge 为控制本地不会保留过多的binlog 文件,定期清理本地的binlog文件。
写入流程
zp_data_partiton.c
if (!cmd->is_suspend()) {
// read lock
pthread_rwlock_rdlock(&suspend_rw_);
}
if (cmd->is_write) {
// lock this key
mutex_record_.Lock(key);
}
cmd->Do(req, &res);
if (cmd->is_write) {
if (res->code() == client::StatusCode::kOk) {
logger_->Put(raw);
}
mutex_record_.Unlock(key);
}
if (!cmd->is_suspend()) {
pthread_rwlock_unlock(&suspend_rw_);
}
目前有两个命令是有suspend tag属性的
// SyncCmd
Cmd* syncptr = new SyncCmd( kCmdFlagsAdmin
| kCmdFlagsRead | kCmdFlagsSuspend);
// FlushDBCmd
Cmd* flushdbptr = new FlushDBCmd( kCmdFlagsAdmin
| kCmdFlagsWrite | kCmdFlagsSuspend);
关于suspend tag 的说明
如果是有suspend 属性的命令需要自己对suspend_rw 加写锁 或者不加锁
如果没有suspend属性一律对suspend_rw加读锁
对于flushdb这种命令,上写锁是为了保证在flushdb的时候,不允许其他的线程写入或者读取。
对于sync 命令,加suspend tag 属性 是为了不加读锁也不加写锁,因为sync 不对数据操作。
Problem ?
由于处理内部通信命令和外部客户端的命令用的同一个port,导致需要为sync这种命令特殊处理。代码可读性降低。内部通信的命令处理可能会影响客户端处理的性能。
提供一个单独的port和线程处理admin命令是比较合理的方式。
1.3 Synchronization
这是zeppelin node的亮点,下面我们详细分析一下。
下面是Master Slave用于同步的主要线程
Master Slave
dispatch thread(zp_data_client_conn) <===== trysync thread
zp_binlog_sender =====> zp_binlog_receiver thread
1, trysync thread 发送请求到dispatch thread是处理客户端的端口上,建立zp_data_client_conn
2, 同步请求建立成功zp_binlig_sender 发送binlog 到 zp_binlog_receiver 专门zp内部通信的端口
全量同步
zeppelin的全量同步依赖于rocksdb的snapshot,通BgSave 线程做rocksdb的当前快照,然后通过rsync进程同步到对端。
增量同步协议
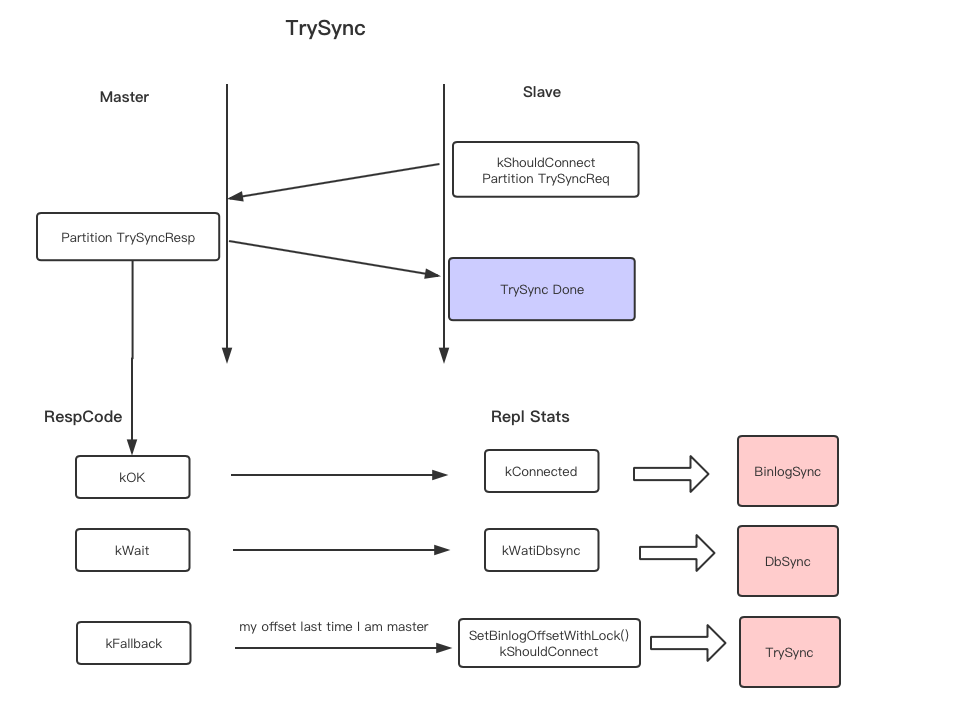
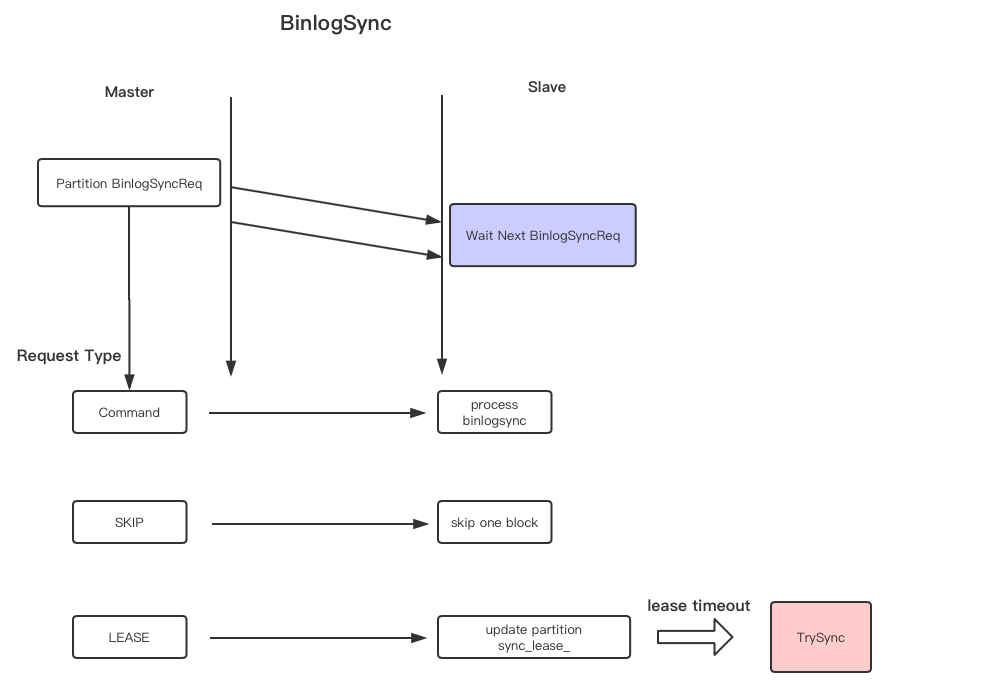
增量同步线程
对于有限的BinlogSender Thread 资源,和动态增加的partition数量,为每一个partition建立一个thread显然是不可能的事情。zeppelin使用了Round-robin 的算法,轮询queue里面的每一个task,每一个partition处理固定的时间片。
1,新加入的partition作为一个task 加入到task_queue当中
2, Binlog Sender Thread轮询task_queue 中的task 按照按照顺序dequeue,处理一个时间片的长度再enqueue。
2,Meta Server
Meta 信息是表示集群拓扑信息和状态的重要结构,Zeppelin 采用的是有中心的meta管理方式。为保证集群对于meta信息认知的一致性,meta是以leader follower的形式存在的。Zeppelin的meta节利用floyd库(raft实现 )实现meta信息的强一致性。
2.1 Meta Info
Zeppelin的meta信息包含信息如下
class ZPMetaInfoStore {
// -2 for uninitialed
// -1 for initialed but no table
// Otherwise non-negtive integer and monotone increasing
// epoch records topology info changes
std::atomic<int> epoch_;
// table => ZPMeta::Table set
std::unordered_map<std::string, ZPMeta::Table> table_info_;
// node => alive time + offset set, 0 means already down node
// only valid for leader
std::unordered_map<std::string, NodeInfo> node_infos_;
}
message Partitions {
required int32 id = 1;
required PState state = 2;
required Node master = 3;
repeated Node slaves = 4;
}
ZPMeta::Table
message Table {
required string name = 1;
repeated Partitions partitions = 2;
}
struct NodeInfo {
uint64_t last_active_time;
// table_partition -> offset
std::map<std::string, NodeOffset> offsets;
}
2.2 Thread Model
下图是zp meta的线程模型
zp_meta的读写分离,为了减少Leader的压力,follower meta提供meta信息的可读服务,对于到达follower写请求,会redirect 到主处理。
红色
Dispatch Thread & Worker Thread: 处理链接meta的请求功能与zp_node相同,详见 zp_node
绿色
Updata Thread : 将meta info写入floyd的线程,采用延迟写入的机制,为减少floyd的压力,对于meta info的变化会缓存一段时间再写入floyd
蓝色
Condition Thread: 一直监控和处理两种符合条件的的task,主要是为migrate用
Condition 1, 如果left node和right node binlog相差一个binlog file,满足 kCloseToNotEqual 条件。 执行注册task时候预定的函数。
Condition 2,如果left node 和 right node binlog 完全相等,满足 kEqual 条件。执行注册task时候预定的函数。
黄色
Cron Thread(Main thread)
void ZPMetaServer::DoTimingTask() {
Status s = RefreshLeader();
if (role_ == MetaRole::kLeader) { // Is Leader
// Check alive
CheckNodeAlive();
// Process Migrate if needed
ProcessMigrateIfNeed();
// leader dont need to refresh table info and node info
// because info will store in leader anyway
} else if (role_ == MetaRole::kFollower) {
// Refresh table info
s = info_store_->Refresh();
// Refresh node info
s = info_store_->RefreshNodeInfos();
}
}
Apply Meta Info Change
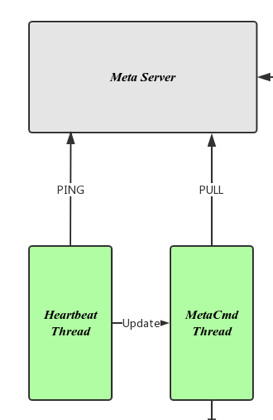
1, meta的管理链接(zeppelin_manger)给zp_meta 下达修改meta的命令(drop table for example), zp_meta 通过zp_meta_update_thread 线程同步到floyd。为防止meta信息的过快更新,对floyd造成过大压力,zp_meta 对修改的meta信息进行了缓存, 过kMetaDispathCronInterval 毫秒会向floyd提交一次这一秒内所有的修改。
2,等zp_node 定时ping zp_meta 发现zp_node 本地的epoch 与zp_meta的epoch 不一样,触发zp_node 从zp_meta pull meta 信息,比较本地内存信息发现没有table a 的信息了,zp_node去除本地关于table a的所有数据。
同理node server初始化
node起来之后 ping meta, 发现需要同步meta 信息,向meta发送pull meta request,
node收到meta 信息之后
1,create table and build partition
2,partition update to open db
Status ZPMetacmdBGWorker::ParsePullResponse() {
for (pull.info_size()) {
// init table table and partition(not open db yet)
std::shared_ptr<Table> table
= zp_data_server->GetOrAddTable(table_info.name());
}
for (table_info.partitions_size()) {
table->UpdateOrAddPartition(partition.id(),
partition.state(), master_node, slave_nodes);
}
}
bool Table::UpdateOrAddPartition(const int partition_id,
ZPMeta::PState state, const Node& master, const std::set<Node>& slaves) {
slash::RWLock l(&partition_rw_, true);
auto iter = partitions_.find(partition_id);
if (iter != partitions_.end()) {
// Exist partition: update it
(iter->second)->Update(state, master, slaves);
return true;
}
// New Partition
std::shared_ptr<Partition> partition = NewPartition(table_name_,
log_path_, data_path_, trash_path_, partition_id, master, slaves);
assert(partition != NULL);
partition->Update(ZPMeta::PState::ACTIVE, master, slaves);
partitions_[partition_id] = partition;
return true;
}
void Partition::Update(ZPMeta::PState state, const Node &master,
const std::set<Node> &slaves) {
// Will open db set db ZPMeta::PState::ACTIVE
// Update role
if (role_ != new_role) {
// Change role
if (new_role == Role::kNodeMaster) {
BecomeMaster();
} else if (new_role == Role::kNodeSlave) {
BecomeSlave();
} else {
BecomeSingle();
}
}
}
void Partition::BecomeMaster() {
Open();
.....
}
void Partition::BecomeSlave() {
Open();
.....
}
void Partition::BecomeSingle() {
Open();
.....
}
Problem?
node 和meta的信息不一致导致问题。meta修改过之后(drop table),node 本地没有更新meta,本地table 也没有 被删除,这时候node突然down,node重启之后并不知道需要删除本地的meta。
Solution:
本地持久化meta信息。pull meta的时候对比删除本地的数据(table for example)。
2.3 Cluster Mangement
作为分布式的存储平台,不可避免的需要调整集群的规模,zeppelin提供了对于partition级别的集群扩容,缩容方案。以如下扩容为例:
Node4 作为新机器加入集群,Node1 上的Partition1 需要迁移到Node4上, Node2 上的partition3 需要迁移到Node4上。
各个线程的配合关系:
1,client接收migrate命令,将命令存入migrate registor 持久化到floyd,返回client 记录迁移完成。
2,cron线程读取migrate registor里面的migrate task,进行迁移
这里只有leader 做迁移的操作
void ZPMetaServer::ProcessMigrateIfNeed() {
migrate_register_->GetN(g_zp_conf->migrate_count_once(), &diffs);
for (diffs) {
s = update_thread_->PendingUpdate(task_addslave);
s = update_thread_->PendingUpdate(task_slowdown);
// when condition matches, tasks need to be added
// to update_thread task queue
std::vector<UpdateTask> updates_stuck = {
task_stuck, // Handover from old node to new
};
condition_cron_->AddCronTask(
OffsetCondition(
ConditionType::kCloseToNotEqual,
table,
partition,
left,
right,
ConditionErrorTag::kRecoverNone
),
updates_stuck);
std::vector<UpdateTask> updates_handover = {
task_handover, // Handover from old node to new
task_active, // Recover Active
};
condition_cron_->AddCronTask(
OffsetCondition(
ConditionType::kEqual,
table_name,
partition,
left_node,
right_node,
ConditionErrorTag::kRecoverMigrate
),
updates_handover);
}
}
Steps:
以 (Migrate table source(ip:port) partition_id destination(ip:port) )
migreate table_test 1.1.1.1:9221 4 3.3.3.3:9221为例
0,未修改的meta info
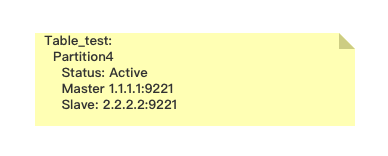
1.1.1.1:9221 简写为 A, 3.3.3.3:9221简写为 B
1,update_therad 修改关于table_test table的meta信息 partition4 addslave B
2,update_thread 修改partition4 的状态为slowdown
由于update_thread 有缓存,通常1,2对于meta的修改在一次floyd提交
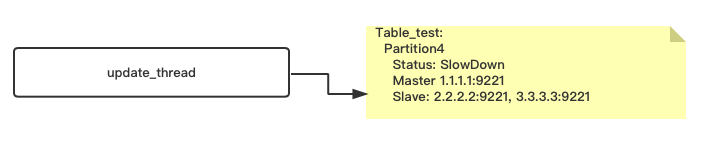
3,通过pull meta,对应的A,B接收到meta修改
4,condition_cron 监控A,B ping 上报的binlog offset信息,当A,B 的binlog filenum(kClosetoNotEqual) 一样,A B的offset 相差小于stuck_offset_dist()大小的时候向update_thread 提交stuck task。
5,通过pull meta,partition 4 master 状态为stuck 拒绝请求
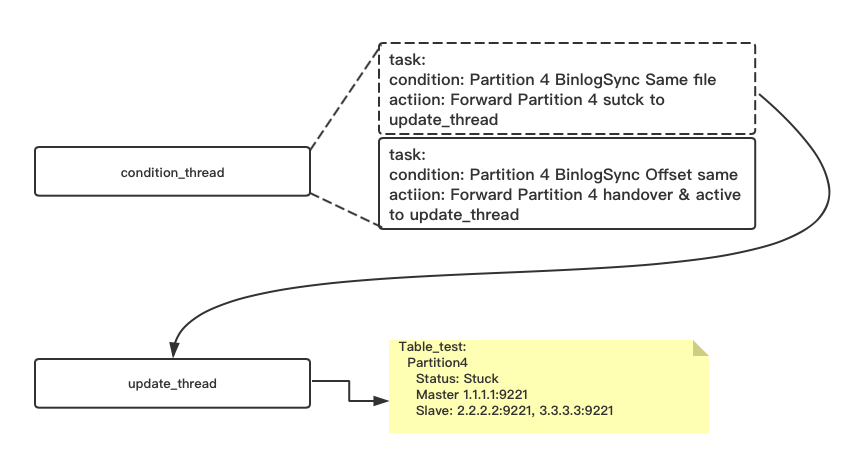
6,condition_cron 继续监控A,B ping 上报的binlog offset 信息,当A,B offset 完全一致的时候(kEqual),向update_thread 提交handover & active task
6 .1 handlover task delete A 作为partition4 slave/master的信息。如果 A是partition4的主,需要修改meta重新任命B作为partition4的主
6.2 将partition4的状态至为Active 重新接受请求
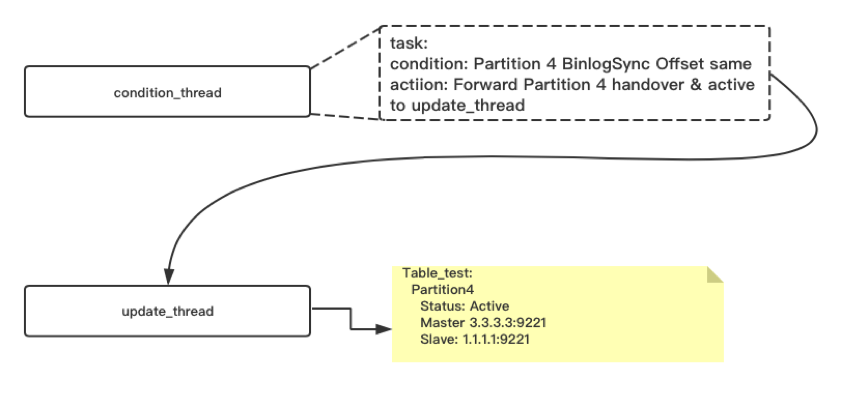
Problem?
这种方式简化了zp_meta 和zp_node 之间的通信协议,基本上之后ping 和 pull 两种请求。但是,正是由于ping发现epoch不一致才会去pull meta信息这种操作,会造成zp_meta 和 zp_node对于meta的信息长时间的不一致,导致一系列问题。
Problem?
slowdown这个状态需不需要值得商榷。addslave之后,这个partition不需要马上slowdown,按理这个partition经过全同步 增量同步应该能追的上master,如果追不上的话再slowdown也不迟,由于全同步是一个很久的过程如果addslave 马上就slowdown了,会让这个partition很久都是slowdown的状态。
Problem?
关于集群管理,由于节点异常meta server 感知后会进行切主,长时间的频繁切主会造成流量不均衡,由于zeppelin读写都只从master partition上进行,频繁切主造成个别node server主特别多,造成流量不均衡。最好的方式能够在切主的时候平衡主分布,在异常node server 恢复之后重新切主回来。
2.4 Leader Election
由于只有Leader接受关于meta的写请求,也只有leader进行migrate操作,所以对于集群来说谁是leader是一个非常重要的信息。Zeppelin的选主操作是通过分布式锁来实现的。
对于主来说会定期的对于这个锁继续上锁续约。对于从来说,只有在发现锁超时了之后会主动抢锁。
对于突然的网络不可用,本地会记录上一次获得主的信息的时间,如果没有超时,那么依旧返回上一次主信息。
对于用分布式锁实现选主,zeppelin 作者是这样认为的:
- 严谨实现:加锁时返回Sequence,这个Sequence自增,获得锁的节点之后的所有操作的受体都必须检查这个Sequence以保证操作在锁的保护中;
- 简单实现:节点在尝试加锁时需要提供一个时间,锁服务保证这个时间内不将锁给其他节点。使用者需要自己保证所有的操作(主要指修改leader meta)能在这个时间内完成。这个方法虽然不严谨但是非常简单易用,Zeppelin的Meta集群采用的正是这种方式。
3,Thanks
本文的许多内容都是借鉴了CatKang的理解,加以自己一段时间的思考加工而成。本文更倾向于代码和实现细节,康神的博客更偏向于原理和设计。
写给看到此文章的人:
Zeppelin可以说是我的入门指导代码,参与了一段时间的开发,以及快一年的运维,我可能是最后一个看完完整的zeppelin的代码的人了。到最后zp被抛弃,心情还挺复杂。代码可能渐渐被人们忘记,但是zp带给我的分布式设计理念我会一直继承下去。下一个江湖再见。
最后附上Zeppelin分享