Introduction to Amazon Dynamo
Dynamo 是一个去中心化的k-v存储系统,它的定位是high availability,无论是任何时候提供能够读写的服务。对于一致性,dynamo提供最终一致性,本文中也提到,在极少数情况下会出现一数据多版本的情况,dynamo会返回给上层处理。尽管dynamo不完美,但是对于去中心化系统的优化值得好好研读。正如文中所说
Dynamo has provided the desired levels of availability and performance
and has been successful in handling server failures, data center failures
and network partitions.
07年至今,4000+ citation,被无数的人所关注,时间已经证明,dynamo是分布式存储系统中的一篇经典论文。
定位:
- 简单的k-v借口,没有提供多数据结构的接口,最适用的场景是小objects(usually less then 1 MB)场景。
- 适用于弱一致性要求的业务,不支持事物。
- 可以满足99.9%的强时延请求。
- 没有做安全方面的需求。
整体来说本文主要考虑如何解决如何实现高可用的k-v存储,即使网络分割(network partitions)或者服务器down掉,依然能够提供存储服务。为了实现always available,论文解决了如下问题:
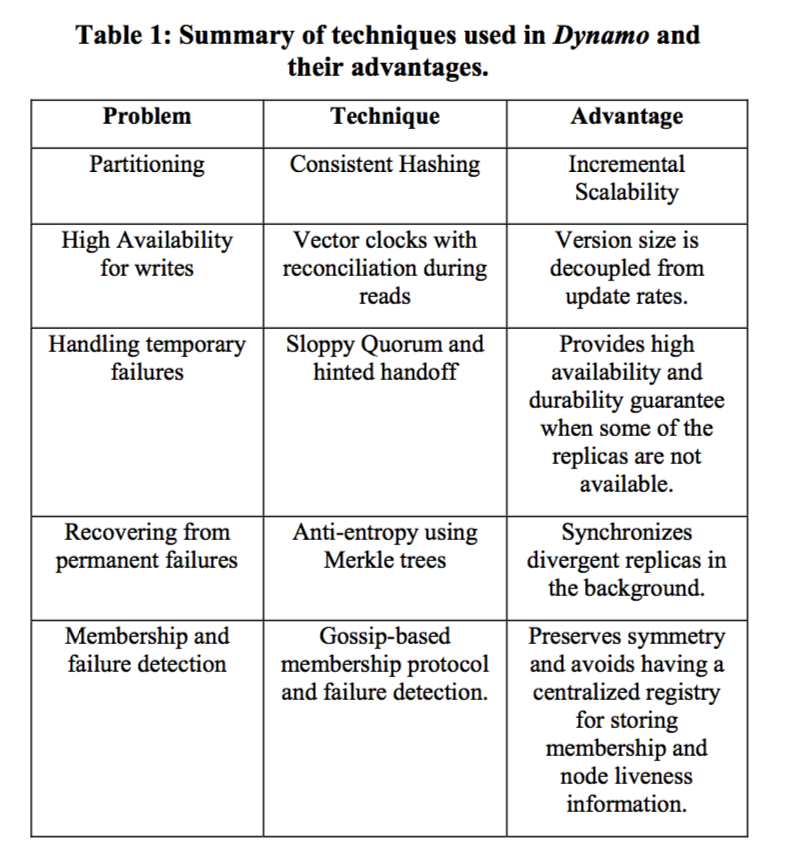
1. Partitioning
为了实现便于扩展的特性,dynamo 选择了一致性哈希,但是由于一致性哈希负载不平衡的问题,这里引入了虚拟节点(virtual node)。
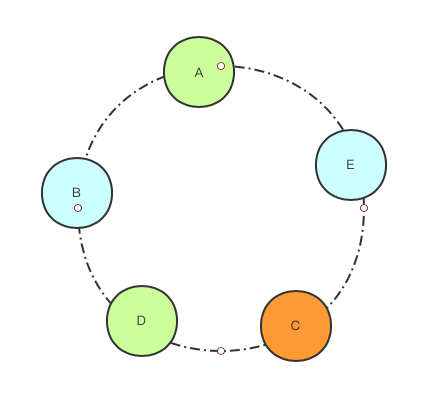
一致性哈希中将哈希空间均匀哈希成多个token,这些token头尾相连组成一个环。然后将节点随机到哈希到环上的不同位置。
可以看出当前的节点分布并不均匀,例如A节点负责(B, A] 的哈希范围,B节点负责(C, B]的哈希范围。由于token是均匀分布,(C,B]的范围显然要高于(B,A]的范围,最终大概率为B的负载高于A的负载。
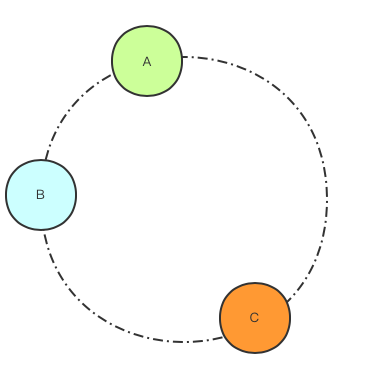
引入虚拟节点之后,每一个物理节点被映射到环上的不同虚拟节点上。
如图A为物理节点,D为物理节点映射出来的虚拟节点。同理,B为物理节点, E为虚拟节点。可以看出每个节点负责的范围相差不大,负载不均衡的情况被有效缓解了。
文中对于dynamo的分片策略进行了进一步的讨论:
此处介绍最优的策略strategy 3。数据空间Q等分,S为系统中拥有的节点数,Q/S为每个节点拥有的分片数目。如果有新节点加入,其将会从其他节点接管分片,如果有节点离开将会把自己的分片交给其他节点负责。
个人理解最初加入了虚拟节点的哈希环上的分片是基本上均匀分布的,节点被哈希到环上的随机位置,但是strategy3中,每个节点负责的分片个数是固定的,但是分片的分布是任意的。这样的做法使得分片的分布更加灵活,对于节点添加删除,可以将整个分片交给任意的节点负责,同时可以保证保证负载的均衡。
2. High Availability for writes
2.1 Replica
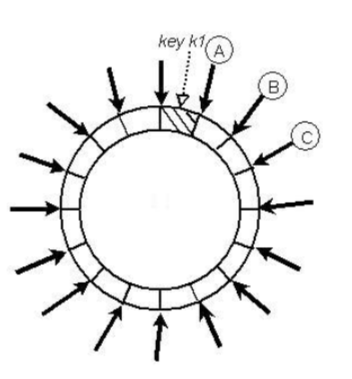
dynamo对于每一次写命令提供了多副本的策略,每一个key会对应到其coordinator node(负责这个key的节点,通常是物理节点)。然后按照环上的顺序依次找到其顺时针连续的N个节点作为数据副本节点。
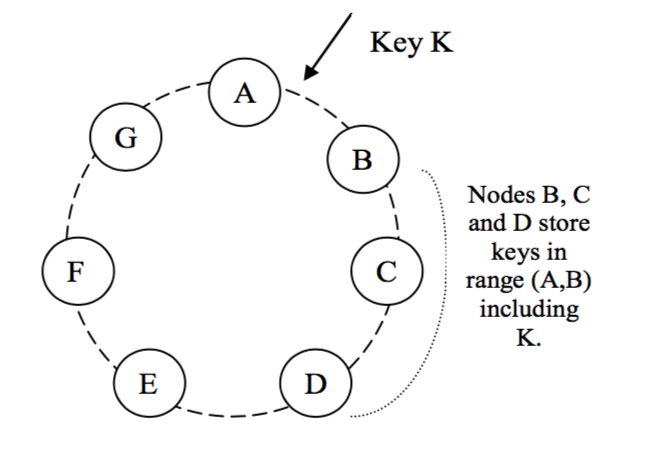
图中采用三副本策略N=3,如果B点为coordinator node,C,D就为副本节点。
2.2 Replica consistency
对于读写操作,dynamo提供了get() 和set() 操作。为了保证副本的一致性,dynamo提供了一个类似于quorum system的协议。
R + W > N
R: 在一次读中必须参与的最小节点个数
W: 在一次写中必须参与的最小节点个数
N: 副本数
2.3 read/write process
读写流程中会先在preference list中找到应该处理该key的coordinator,这个list中的node 会尽量包含物理节点而不是虚拟节点。之后,对于读写流程需要除本节点外读R-1个节点的内容或者等待W-1个节点的写返回。
虽然在2.2中dynamo提出了一种写多副本的策略来保护数据的一致性,然而在一些极端情况下,冲突(版本分歧)还是会出现。本节提供了一种处理分歧的方式。
文中为更好的说明这一现象定义了vector clock
vector clock = object([node, counter], ...)
node = 机器id
counter = 该数据在node上的处理序序号
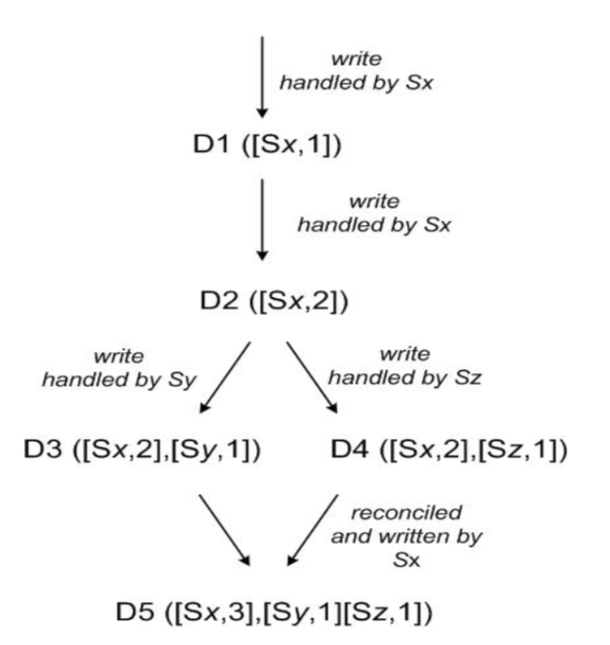
考虑如下场景,clientA写入D1,接下来写入D2 覆盖了D1,然后Sx挂了,clientA写入D3到Sy中。这时候在D3写W-1个副本的时候clientB写入D4到Sz中,这样就发生了分歧。如果有clientC同时读到了D3和D4(w次读),读到的应该是D3和D4的集合,(Sx, 2) (Sy, 1) (Sz, 1) 。如果是client端处理这种分歧的话,client将会把这个数据再写入Sx中完成分歧处理。最终的数据是D5当中的样子。
3. Temporary Failures
对于节点短暂的不可用,dynamo采用了Hinted Handoff的策略,其流程是先将client的request转移到其他的节点B(not coordinator node A),然后等到coordinator node A可用的时候,将之前暂时存在B 点的数据转移到节点A上。A节点接下来继续提供服务。
4. Replica Synchronization
对于永久性离开的节点,dynamo提供了副本同步的机制,可以同步副本之间的数据。为了更快的检查副本之间需要同步的数据,dynamo引入了merkle tree。Merkle tree用来标记每一个node上面对于一段范围的数据是否一样。进而确定需要同步的的数据。但是由于引入了Merkle tree对于节点的加入和删除将会引入大量的Merkle tree重新计算。
5. Failure Detection
dynamo采用了gossip的策略。每个节点都会维护一个完整的环上成员信息(membership information), 该信息的更新就是通过gossip策略将环上的成员信息变化传递到周围节点上。
总而言之,dynamo对于数据分布,容错处理,数据恢复,元信息传递等问题进行了整体的讨论。虽然代码没有开源(很可惜),但是对于稳定运行多年的系统,时间就是检验技术的最好的标准。或许dynamo并不完美,但是dynamo是一个很好的教科书般的无中心节点分布式存储的实践。有时间的小伙伴可以看看原文。希望本文不要误人子弟。