Ceph恢复流程 详述
在Ceph恢复流程 概述一文中简述了Ceph的数据恢复流程,主要副本资源预约,到线程处理,到消息处理,进行object的恢复。在线程处理过程当中,对于主的线程是如何做恢复,以及backfill的恢复流程是怎样的,这两个问题都没有解释的特别清楚。本文将对于这两个问题进行详细的解释。文末会针对于测试集群的一些现象给出一些合理的解释以及一些思考。
-
Recovery
recovery流程中最重要的一部分流程是收集各个从缺少的objects,以及计算从osd缺少的object在哪里有相应的副本。这一部分是由peer流程和active状态机初始化流程一同完成的。在peer流程中的GetMissing阶段中,根据各个peer传输过来的log消息,与权威log进行比较,从而计算出该peer缺失的objects,存放在peer_missing结构中。在active初始化过程中,根据peer流程中获得的peer_missing信息,计算出缺失的objects在哪个peer上存在,存放在missing _loc结构中。Recovery依赖于之前获得的pg_missing_t和missing_loc结构。下图完整的呈现了,recovery流程中所需要的数据结构关系。
PG中包括peer缺失哪些objects的信息,保存在peer_missing结构中。缺失信息在哪些peer上有,存在Missing_loc中。以及下图中分别列出了pg_missing_t和Missing_loc等关键的数据结构。
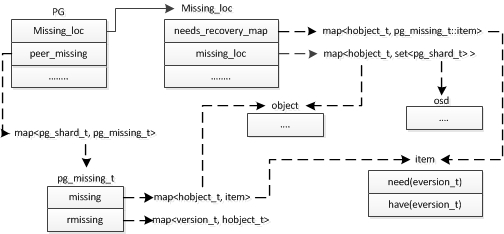
图1引自 一只小江
对于Recovery流程,所有恢复行为都是由主发起的,从只是被动的接受消息并且根据消息进行处理和状态转换。主在进行从恢复的时候,会尝试从本地向从 push object。如果本地没有这个obejct,主会先从missing_loc中选一个peer恢复自己,然后再恢复从。最终调用pgbackend类的run_recovery_op函数发送消息。
-
Backfill
Backfill的流程相对于recovery来说要复杂。Backfill触发的场景是PG不能够通过log来恢复,需要主和从进行全同步。全同步的过程会比较本地的包含objects信息的哈希表集合,跟各个OSD的包含objects信息的哈希表集合进行比较。值得注意的是这里是按照object的哈希顺序进行比较的。(obj1, obj5, obj6……)
以下为backfill恢复的具体流程。
借用Ceph源码分析中的一个经典例子:
position 0 1 2 osd0 obj4 1,1
last_backfill
peer_backfill_info[0].beginobj5 1,4 obj6 1,10 osd1 obj5 1,3
last_backfill
peer_backfill_info[1].beginosd2 obj4 1,1
last_backfill
peer_backfill_info[2].beginobj6 1,4 osd3 obj6 1,1
last_backfill
peer_backfill_info[3].beginobj7 1,8 osd4 obj5 1,4
last_backfill
peer_backfill_info[4].beginobj6 1,10 osd5
primaryobj5 1,4
backfill_info.beginobj6 1,10 last_backfill_started osd5为主,last_backfill_started是上一次backfill的位置,每个OSD的恢复的范围的起点是所有的peer中last_backfill最小的位置。上述表中对应的是position 0 (obj4)。终止的位置是每个OSD最新更新的object的位置。
1 . 初始化check指针指向起始位置position0(obj4),各个osd的pos 0位置与本osd的backfill_info.begin进行比较。如果比backfill_info.begin小。
由于object是按照哈希序排列的,所以主中的恢复序列一定没有obj4,也就是说osd0和osd2中需要移除obj4。
将osd0和osd2的peer_backfill_info[0].begin 和peer_backfill_info[2].begin 更新至pos1。
更新后如下表所示
osd0 obj4 1,1
last_backfillobj5 1,4
peer_backfill_info[0].beginobj6 1,10 osd1 obj5 1,3
last_backfill
peer_backfill_info[1].beginosd2 obj4 1,1
last_backfillobj6 1,4
peer_backfill_info[2].beginosd3 obj6 1,1
last_backfill
peer_backfill_info[3].beginobj7 1,8 osd4 obj5 1,4
last_backfill
peer_backfill_info[4].beginobj6 1,10 osd5
primaryobj5 1,4
backfill_info.beginobj61,10 last_backfill_started 2 . 将check指针指向object5,这时候check等于backfill_info.begin。之后的流程check会随着backfill_info.begin更新。之后的流程中check等于backfill_info.begin。
如果backfill_info.begin等于peer_backfill_info[i].begin, (osd0, osd1, osd4)
osd0或者osd4的版本与backfill_info.begin一样。不用做任何改变。
osd1 版本不对需要加入need_version_targs队列,进行恢复。
如果backfill_info.begin不等于peer_backfill_info[i].begin, (osd2, osd3)
osd2 的last_backfill < backfill_info.begin 将obj5加入missing_targs中。
(last_backfill指针的意思是backfill已经恢复了的object,osd2已经恢复了obj4,last_backfill对应的object在主的恢复序列之前,所以主当前恢复的obj5在osd2中应该是丢失的,需要注意的是osd2的peer_backfill_info一定是大于等于obj5的,因为小于的object全在步骤1当中加入需要移除的队列中了)
osd3 的last_backfill > backfill_info.begin, 说明osd3已经恢复了obj6了,obj5必定恢复完了,不需要做任何处理。
更新信息
对于peer_begin.begin 等于 check的osd, peer_backfill_info[i]右移
last_backfill_started = backfill_info.begin
backfill_info.begin 右移
osd0 obj4 1,1
last_backfillobj5 1,4obj6 1,10
peer_backfill_info[0].beginosd1 obj5 1,3
last_backfillpeer_backfill_info[1].begin osd2 obj4 1,1
last_backfillobj6 1,4
peer_backfill_info[2].beginosd3 obj6 1,1
last_backfill
peer_backfill_info[3].beginobj7 1,8 osd4 obj5 1,4
last_backfillobj6 1,10
peer_backfill_info[4].beginosd5
primaryobj5 1,4
backfill_info.beginobj61,10 last_backfill_started 3 . 发送对于所有缺失的objects
-
recovery vs backfill的说明
recovery 和backfill 两种恢复状态是可以同时存在的。当同时存在的时候,先进行recovery等待recovery全部恢复,再进行backfill。
什么情况下会出现需要做两种恢复的情况呢?
假设从osd下线一段时间以后再上线,这时候log已经与主的log完全不重合,需要backfill(图中A点)。由于需要扫描的objects比较多,backfill流程进行很缓慢,这时候该osd由于网络等原因短暂掉线,重新上线之后需要进行recovery(图中B点,通过分歧log进行recovery)。这时候上一次的backfill还没有完全完成,所以需要主先对于该osd进行recovery,等待recovery完成再进行backfill操作。
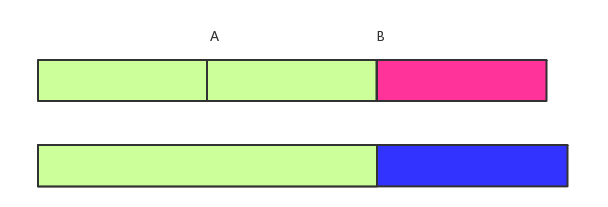
图2 为什么这么麻烦?
如果直接从上一次的backfill地方开始直接全量恢复可不可以呢?肯定是可以的。区别在于ceph的这种设计时使得该osd尽量跟上当前client更新的objects。对于缺失的需要backfill的object让他们慢慢恢复。backfill的开销要比recovery的开销大很多,尽量先尽可能多的进行recovery恢复,可以减少恢复的时间。
-
从测试结果看ceph的数据恢复流程
ceph的恢复流程支持线程在一次调用中恢复多个甚至所有的objects。但是事实上,测试集群中每次线程调用恢复object的量都是1个。其部分代码如下
int max = MIN(cct->_conf->osd_recovery_max_active - recovery_ops_active, cct->_conf->osd_recovery_max_single_start); "osd_recovery_max_active": "3", "osd_recovery_max_single_start": "1",进行恢复时,osd中会计算当前允许最大的恢复数量max。这个值是当前剩余的可操作数和默认设置操作数中小的那个数值。由于默认操作数
"osd_recovery_max_single_start": "1", 所以max的数值不会超过1。那么,为什么设置这样的初始值?
ceph的设计是优先处理client的请求的。对于数据恢复流程,可以在不占用太对资源的情况下默默的完成。从前面讲到的资源预约和这里的保守的参数初始值,都可以看出数据恢复有可能会占用过多的资源导致osd过忙。要限制这种情况的发生,所以这里给的默认值非常保守。另一方面考虑,这里由于线程的处理非常简单,调用也很频繁,实际上的恢复时间还是非常短的,所以线程一次启动恢复1个object还是可以接受的。