Ceph恢复流程 概述
概述
对于PG来说,状态转移基本上会从initial到peering到recovery到backfill。之前已经介绍过Ceph的状态机转换流程以及peering流程,具体过程详见CEPH_PG_PEERING和PG_STATUS。本文会介绍recovery和backfill的处理流程。Recovery和backfill是Ceph数据修复中最重要的两个部分。在进行recovery和backfill流程之前,peer流程会依据replica的log计算出每个peer缺少的objects。Recovery流程根据各个peer的objects缺失情况,primary会通过向peer请求或者拉取数据的方式,优先完成primary的修复,然后进行replica的修复。对于不能依靠log恢复的PG,在Recovery流程结束后, primary会对这部分PG进行backfill全量恢复。
数据恢复流程主要分为三个部分
- 资源预约流程
- 线程处理流程
- 消息处理流程
资源预约(Resource Reserve)
-
Recovery Resource Reserve
图1,是Recover的状态机转移图。图中,WaitLocalRecoveryReserved和WaitRemoteRecoveryReserved是在处理线程处理之前的资源预约流程。所谓的资源预约,是为了限制正在recovery和backfill的PG的个数。默认情况下配置为1。
"osd_max_backfills": "1"
本地资源预约主要是异步预约,在有闲置资源的情况下调用注册时写好的回调函数,完成本地资源预约。具体来讲是回调函数触发LocalReserveryReserved事件,使状态机转移到WaitRemoteRecoveryReserved。此状态中会向Replica发送RequestRecovery消息。同样,replica收到消息也会完成本地预约,返回MRecoveryReserve消息,通知Primary 已经完成远端资源预约。随AllRemotesReserved事件的触发,状态机会转移到Recovering状态。这时recovery的资源预约已经全部完成,接下来就是下一步的线程处理流程。
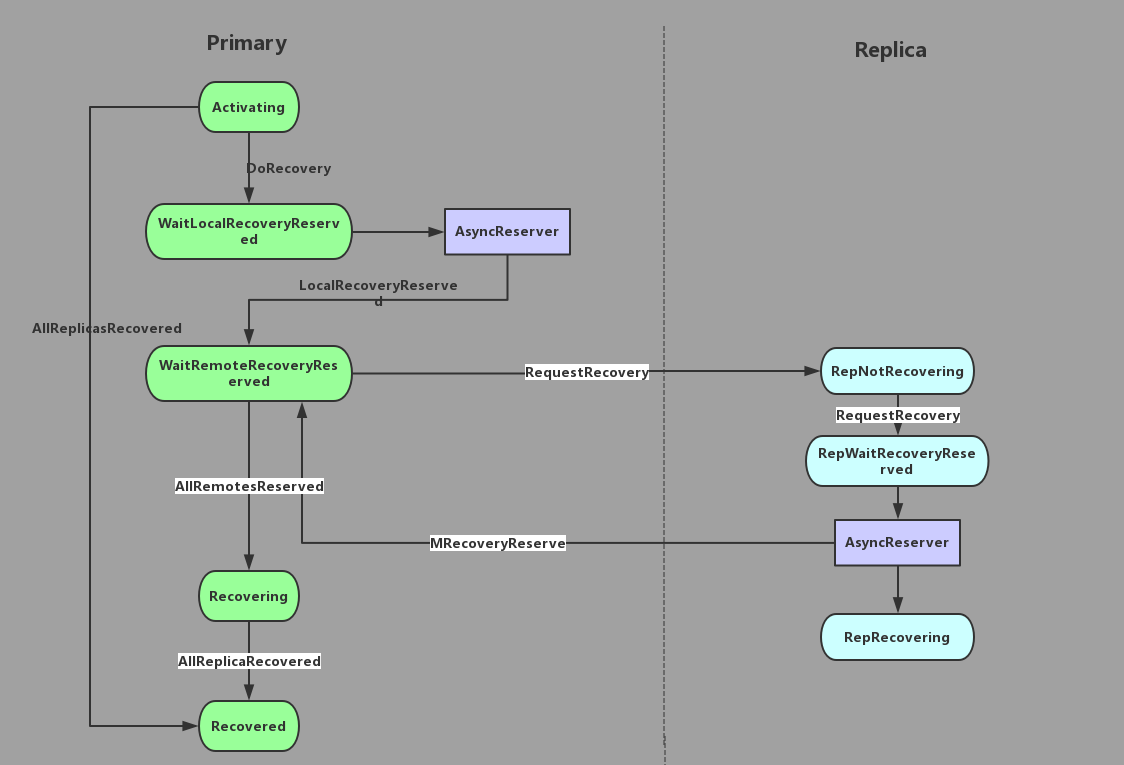
图1 -
Backfill resource reserve
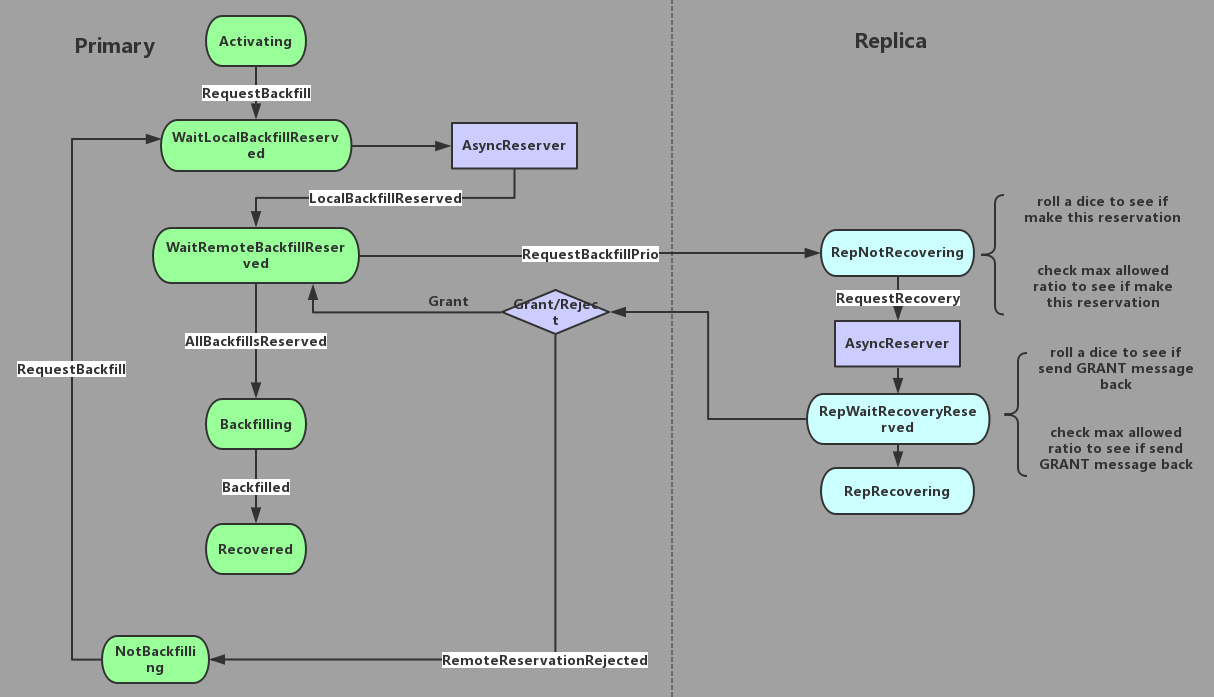
图2 基本上Recovery和Backfill使用的同样的本地预约流程。唯一不同的是远端资源预约。从 图2 可以看出,对于backfill来说,在进行Replica远程预约资源的时候,replica有一定概率拒绝此次预约。
默认参数为
"osd_debug_reject_backfill_probability": "0",同时,如果当前有过多的PG在进行backfill,远端replica也会拒绝此次预约请求。如果被拒绝,primary会进入NotBackfilling,一段时间以后PG会定时产生一个RequestBackfill事件将状态机转移到WaitLocalBackfillReserved并重新进行资源预约。
线程处理(Thread Process)
recover和backill的流程都是active状态的子状态。active状态下的PG是可以提供读写服务的。也就是说,recover和backfill是在集群可提供服务后的行为。事实上ceph专门提供了一个专门的线程池来实现recovery和backfill的功能。
线程会调用OSD的do_recovery函数
-
计算最大能够操作的操作数(operations)
一般情况下此操作数等于能够恢复objects的数目
-
调用pg->start_recovery_ops(),将此参数传入需要恢复的PG中
在PG中(pg->start_recovery_ops)
- 先恢复primary
- 当primary完全恢复,尝试恢复replica
- 如果primary和replica恢复完成,并且完成backfill资源预约。尝试backfill。
- 如果recovery完成或者backfill完成,抛出相应事件进行状态机转移。
对于recovery和backfill的顺序,在PG中是严格保证的。顺序一定是先尝试Primary恢复,再replica恢复。当recovery完成时,进行步骤4推动状态转移。经过状态转移从recovering转移到WaitLocalBackfillReserved,进行backfill资源预约,再进行线程处理调用start_recovery_ops。这时候,因为recovery恢复完成,跳过步骤1,2,进行PG当中的步骤3。如果backfill完成,再进行步骤4。最终状态会转移到Recoved状态,完成恢复流程(包括recover和backfill)。
消息处理流程(Message Process)
recovery或者backfill流程当中消息报文的交互过程如下如图所示
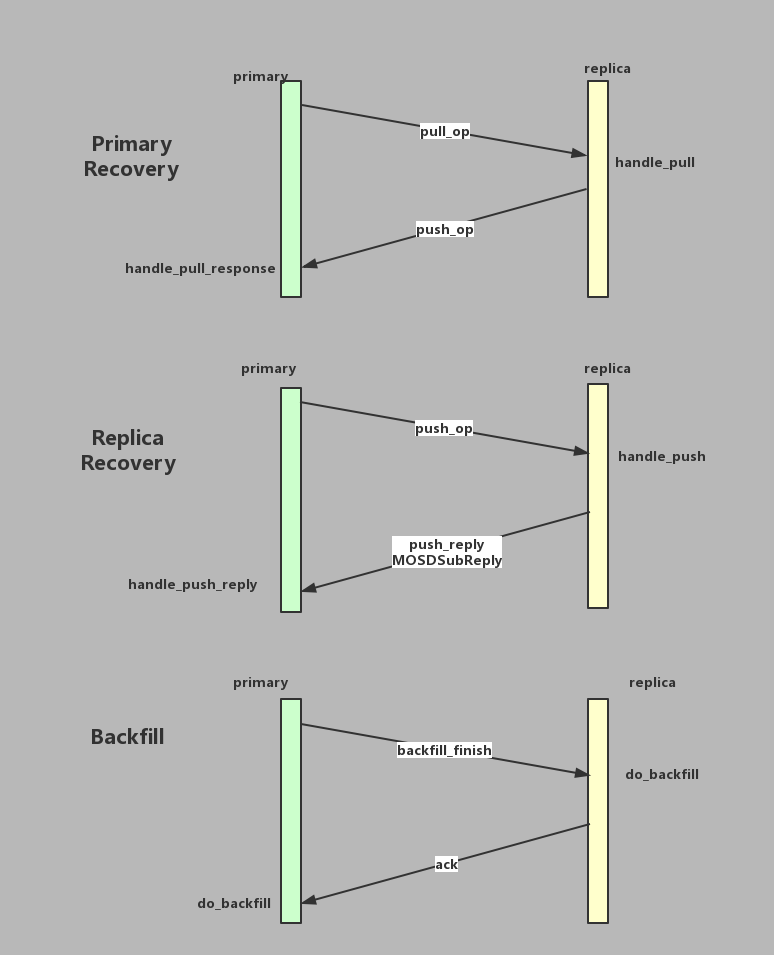
图3 中分别注释了收到消息之后的处理函数。例如在primary恢复自己的时候,会发送push_op请求到replica上,replica会调用handle_pull函数进行处理。具体的处理流程读者有兴趣可以去读下source code。
值得注意的是在恢复过程当中,primary和replica的“地位”是不平等的。只有primary是recover replica和backfill的发起者,primary会根据replica缺失的objects向replica发送相应的push消息。反观replica,只是根据primary的消息作出相应的动作,受primary消息牵引进行状态转移。
总结
以上就是ceph的数据修复的概述。便于讲述本文从三个方面阐述了数据恢复的流程,实际上,资源预约的流程在进入Recovering 和Backfilling的时候就结束了,由于是线程进行恢复工作。在Recovering和Backfilling状态中只是将PG放入恢复的队列当中,线程会从队列读取需要恢复的PG信息,进行恢复。在线程恢复过程中,会不断的根据需要接发消息,进行消息的处理。由于最大操作数的限制,未恢复完全的PG,下一次线程做恢复的时候会继续对这个PG恢复,直到恢复完成。
对于线程的详细处理流程,以及更加具体的恢复流程将陆续上传。预知恢复详情,且听下回分解。