A glimpse of Ceph PG State Machine
Introduction:
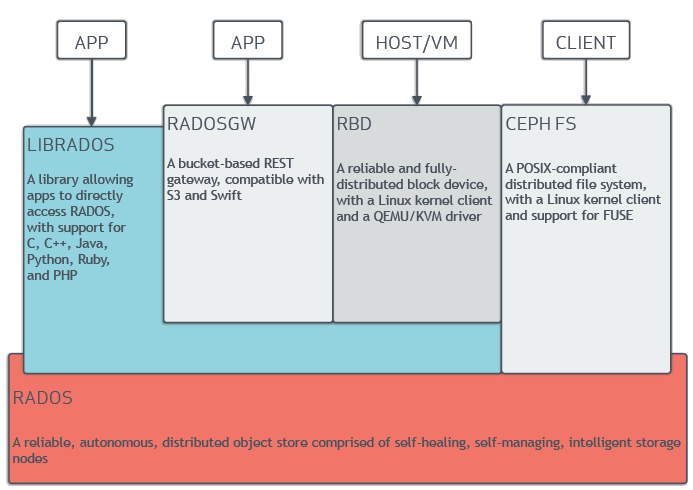
Ceph is a highly reliable, highly scalable, distributed open-source storage system. The pic below is an architecture of ceph.
RADOS (Reliable, Autonomous, Distributed Object Storage) is the base of the system. RADOS allows nodes in the cluster to act semi-autonomously to self-manage replication, failure detection, and failure recovery. More details on RADOS: A Scalable, Reliable Storage Service for Petabyte-scaleStorage Clusters.
Above RADOS layer, LIBRADOS, as it shows in Pic, is a library which supports direct access to RADOS in multiple languages. RADOSGW, RBD and CEPHFS are higher level layers to covert RADOS object storage into bucket-based, block-based and filesytem service.
Why PG state?
PG is the minimum unit to perform reliable storage. For the most to debug work, PG state is the first parameter we may focus on. The description of PG state can be found in Ceph Website.
This article will explain the following two questions.
What is the PG state mean in the source code level and under what condition it will bring PG to some specific state(like CREATING, PEERING).
What PG state machine looks like?
Generally, it is just like the pic below. In ceph, state machine is called “recovery state machine”.
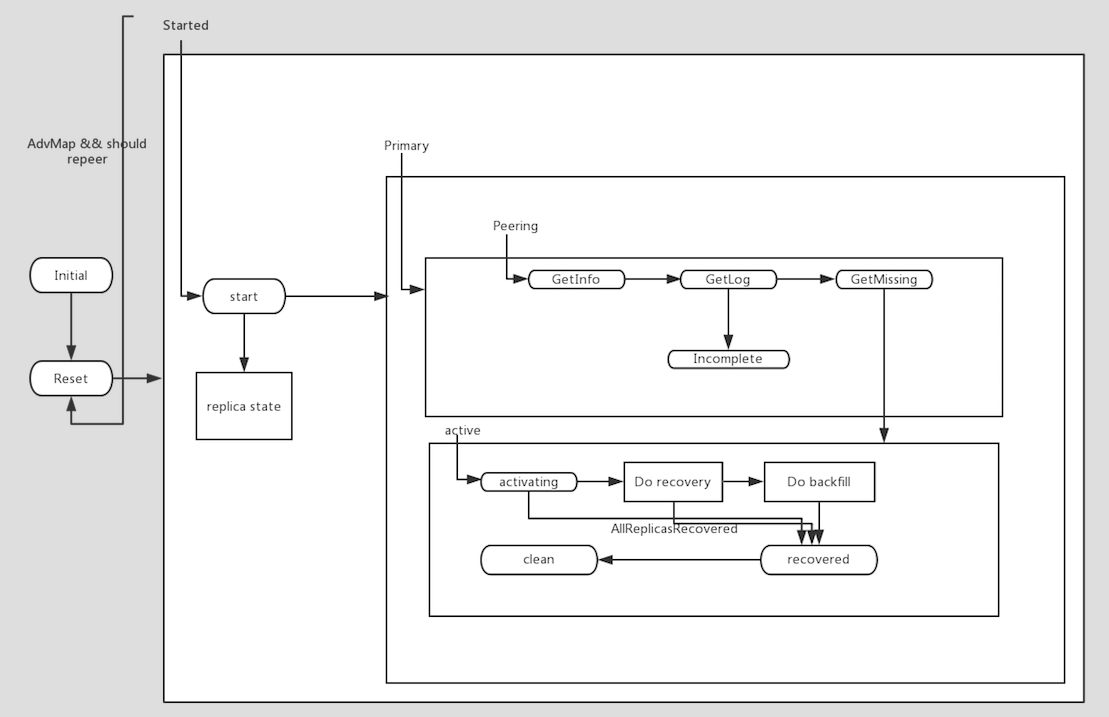
Every PG maintains a state machine. It defines like:
class RecoveryMachine : state_machine< RecoveryMachine, Initial >
Every state machine contains two important elements, states and events. States describe the current PG status. Events lead the state changing. Once one state received a specific event, it will handle this event and it may change to another state.
- state
The code fragment below defines state Initial.
Initial handles two events, Initialize and Load.
“transition” means it will transfer to Reset state once Initialize event happened.
“custom_reaction” is some kind of customized reaction. This reaction will be done after Load event happened.
struct Initial : state< Initial, RecoveryMachine >, NamedState {
explicit Initial(my_context ctx);
void exit();
typedef boost::mpl::list <
boost::statechart::transition< Initialize, Reset >,
boost::statechart::custom_reaction< Load >,
> reactions;
};
- sub-state
Another concept is sub-state.
State Started is defined to be a state in RecoveryMachine.
The code fragment defines sub-state Primary. It is part of Started state and it starts from its substate peering.
struct Started : state< Started, RecoveryMachine, Start >, NamedState{};
struct Primary : state< Primary, Started, Peering >, NamedState {};
- event
struct Initialize : boost::statechart::event< Initialize > {
Initialize() : boost::statechart::event< Initialize >() {}
};
Create PG(Pool)
I will take the PG initialization as an example to go though Recovery Machine. That will give us a whole picture of what is the meaning of each state.
-
First time Create PG
client request—->monitor—->OSD
The process starts from a client request to monitor. Monitor will send a pg create message to OSD. The entry to handle this message is
OSD::handle_pg_createFor each PG, its initailized state is
Initialand it will handle two event “Initialize” and “ActMap”. That will lead the PG to be “started” state. If PG is primary, then state transform to Peering to Active and even to clean. That is we called active+clean.OSD::handle_pg_create { for (number of pg monitor request) { create PG//The state is initial //received Initialize event, transform to reset PG::recovery_state.handle_event(Initialize); //reveived ActMap event, transform to Started PG::recovery_state.handle_event(ActMap); } }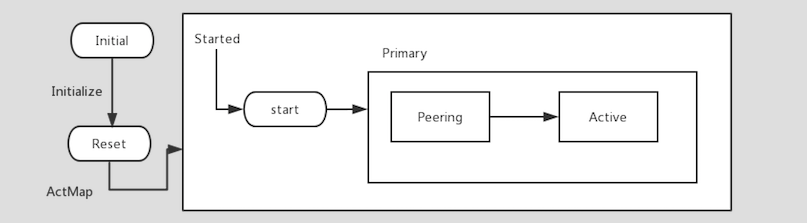
Initial—(Initialize)—>Reset—(ActMap)—>Started—(isPrimary)—>Primary—>Peering —>Active
-
osd restart
Another way to initialize a PG state is restart. Its entry is
OSD::init(). It will:- Load PGs
- Make PG state handle Load event
- PG will transform from
InitialtoResetto Started to Primary to Peering to Active.
OSD::init() { load_pgs recovery_state.handle_event(Load); } PG::RecoveryState::Initial::react(const Load& l){ …… return transit< Reset >(); }Initial—(Load)—>Reset—(ActMap)—>Started—(isPrimary)—>Primary——>Peering —>Active
User visiable state and recovery state
All the states mentioned above are all revocery states. They helps PG to vecovery from different situation. Another state is User Visiable state. It could be considered to be a simplified human readable recovery state machine. States in commands like “ceph pg dump_stuck inactive|unclean|stale” are all User Visiable states. Start from “ceph pg xxxx query” command”, I will focus on the relation between “User Visiable State” and “Recovery State”. As the output below shows, the first line is “User Visiable State”. User Visiable State includes states like active, clean, degraded, peering and so on. Corresponding macro is listed below. More details can be found in ceph/osd_types.cc.
ceph pg {poolnum}.{pg-id} query
{
"state": "active+clean",
"up": [
1,
0
],
"acting": [
1,
0
],
.....
.....
"recovery_state": [
{
"name": "Started\/Primary\/Active",
"enter_time": "2013-01-23 09:35:37.594691",
"might_have_unfound": [
],
},
]
}
PG status (from osd_types.h)
#define PG_STATE_CREATING (1<<0) // creating
#define PG_STATE_PEERING (1<<12) // pg is (re)peering
#define PG_STATE_ACTIVE (1<<1) // i am active. (primary: replicas too)
#define PG_STATE_CLEAN (1<<2) // peers are complete, clean of stray replicas.
#define PG_STATE_DEGRADED (1<<10) // pg contains objects with reduced redundancy
#define PG_STATE_RECOVERING (1<<14) // pg is recovering/migrating objects
#define PG_STATE_BACKFILLING (1<<20) // [active] backfilling pg content
#define PG_STATE_REMAPPED (1<<18) // pg is explicitly remapped to different OSDs than CRUSH
However, under what condition it will change from one user visiable state to another? And what is the real recovery state in source code?
I will brifely go though these user visiable states.
1.PG_STATE_CREATING
This bit will be set when you creating number of PGs in a Pool.
It happens in “Primary” recovery state.
The condition “pg->info.history.last_epoch_started == 0” means it is the first time creating this PG.
- set(PG_STATE_CREATING)
PG::RecoveryState::Primary::Primary(my_context ctx) {
// set CREATING bit until we have peered for the first time.
// When you create a pool, it will create the number of placement groups
// you specified.
if (pg->info.history.last_epoch_started == 0) {
pg->state_set(PG_STATE_CREATING);
}
}
When you are out of Primary state, PG will clear PG_STATE_CREATING bit.
- state_clear(PG_STATE_CREATING)
void PG::RecoveryState::Primary::exit(){
g->state_clear(PG_STATE_CREATING);
}
PG::RecoveryState::Active::react(const AllReplicasActivated &evt) {
pg->state_clear(PG_STATE_ACTIVATING);
pg->state_clear(PG_STATE_CREATING);
//min_size; ///< number of osds in each pg
if (pg->acting.size() >= pg->pool.info.min_size) {
pg->state_set(PG_STATE_ACTIVE);
} else {
//Peer finished not enough osd cant move to active. wait for osd up.
pg->state_set(PG_STATE_PEERED);
}
}
2. PG_STATE_PEERING
Peering process is to bring all its peers into a aggrement about the state of objects in the PG. More specific, it will generate an authoratative log and calculate objects to revocery or backfill.
According to RADOS: A Scalable, Reliable Storage Service for Petabyte-scaleStorage Clusters, “Any locally stored PGs whose active list of OSDs changes are marked must re-peer.” The possible conditions like
- osds down or osds join
- Initialize PG
- modified your CRUSH map, PG is migrating
-
state_set(PG_STATE_PEERING)
PG::RecoveryState::Peering::Peering(my_context ctx) { assert(!pg->is_peered()); assert(!pg->is_peering()); assert(pg->is_primary()); pg->state_set(PG_STATE_PEERING); } -
state_clear(PG_STATE_PEERING)
1.Peering exit
void PG::RecoveryState::Peering::exit() { pg->state_clear(PG_STATE_PEERING); }2.GetLog incomplete
It is impossible to generate authoratative log. For example, all peers are down. It will geos into incomplete state and clear bit PG_STATE_PEERING.
PG::RecoveryState::GetLog::GetLog(my_context ctx){ //calculate the desired acting //calculated acting set size is less than min size(min_size) //to recovery //"choose_acting failed, below min size" //"choose_acting failed, not recoverable" post_event(IsIncomplete()); }
//Started/Primary/Peering/Incomplete PG::RecoveryState::Incomplete::Incomplete(my_context ctx) { pg->state_clear(PG_STATE_PEERING); pg->state_set(PG_STATE_INCOMPLETE); }
3. PG_STATE_ACTIVE
Once Ceph completes peering process, PG becomes ”active”. That basically means this PG is able to serve write and read operations.
-
state_set(PG_STATE_ACTIVE)
To set state PG_STATE_ACTIVE, it follow the logic below:
- In
Activerecovery state, PG registers to a thread. Once receiving any replica reply info, it calls “_activate_committed”. - If primary PG got all replicas, it posts a AllReplicasActivated() event.
- Followed by AllReplicasActivated event, if it matches condition (pg->acting.size() >= pg->pool.info.min_size), it set PG_STATE_ACTIVE bit.
Here is the explaination of “pg->acting.size() >= pg->pool.info.min_size.” For example, we define a strategy that one primary pg need 3 replicas. And the minimum number of PG to be UP is 2(min_size). Normally, the acting size is 3 >= min_size 2. However, if one OSD down, the acting size is 2 >= 2. It will also bring PG to be active. It serves write and read operation as normal. Of course, it is in active+degraded status. I will mention
degradedlater. - In
PG::RecoveryState::Active::Active(my_context ctx){
//regist when we commit call PG->_activate_committed
}
void PG::_activate_committed(epoch_t epoch, epoch_t activation_epoch)
{
if(is_primary()) {
if (peer_activated.size() == actingbackfill.size()){
all_actived_and_committed();
}
} else {
if (acting.size() >= pool.info.min_size){
state_set(PG_STATE_ACTIVE);
}
}
}
/*
* update info.history.last_epoch_started ONLY after we and all
* replicas have activated AND committed the activate transaction
* (i.e. the peering results are stable on disk).
*/
void PG::all_activated_and_committed(){
dout(10) << "all_activated_and_committed" << dendl;
//call Active::react(const AllReplicasActivated &evt)
queue_peering_event(CephPeeringEvtRef(AllReplicasActivated()));
}
Active::react(const AllReplicasActivated &evt) {
//min_size; ///< number of osds in each pg
//active status means able to serve this pg, it doesnt mean all
//replica ack back. acting size bigger then the setted min size,
//it is able to set PG_STATE_ACTIVE. Serve this pg means it is
//able to recover pg under this acting size.
if (pg->acting.size() >= pg->pool.info.min_size) {
pg->state_set(PG_STATE_ACTIVE);
}
else {
pg->state_set(PG_STATE_PEERED);
}
}
-
state_clear(PG_STATE_ACTIVE)
Clear PG_STATE_ACTIVE, when repeer is needed.
/* Called before initializing peering during advance_map */
void PG::start_peering_interval()
{
// deactivate.
state_clear(PG_STATE_ACTIVE);
state_clear(PG_STATE_PEERED);
state_clear(PG_STATE_DOWN);
state_clear(PG_STATE_RECOVERING);
}
4. PG_STATE_CLEAN
When ceph replicaed all objects correct number of times, PG set PG_STATE_CLEAN bit.
-
state_set(PG_STATE_CLEAN)
//Started/Primary/Active/Recovered PG::RecoveryState::Recovered::Recovered(my_context ctx) { //finish recovery assert(!pg->needs_recovery()); //finish backfill assert(!pg->actingbackfill.empty()); if (context< Active >().all_replicas_activated) post_event(GoClean()); } //Started/Primary/Active/Clean PG::RecoveryState::Clean::Clean(my_context ctx){ state_set(PG_STATE_CLEAN); } -
state_clear(PG_STATE_CLEAN)
1.When PG needs to do repeer, clear bit.
/* Called before initializing peering during advance_map */ void PG::start_peering_interval{ //Any locally stored PGs whose active list of OSDs changes are //marked must re-peer. state_clear(PG_STATE_CLEAN); }2.Exit clean state
void PG::RecoveryState::Clean::exit(){ pg->state_clear(PG_STATE_CLEAN); }3.When scrub is working, clear bit.
//if the scrub process is working, then set_clear PG_STATE_CLEAN bool PG::scrub_process_inconsistent(){ state_clear(PG_STATE_CLEAN); }
5. PG_STATE_DEGRADED
There are two cases that could lead PG to be PG_STATE_DEGRADED
- If a peer OSD is down, but primary PG it is still active. PG_STATE_DEGRADED will be set.
- While you cannot read or write to unfound objects, you can still access all of the other objects in the PG. PG_STATE_DEGRADED will be set.
-
state_set(PG_STATE_DEGRADED)
-
state_clear(PG_STATE_DEGRADED)
Active::react(const AdvMap& advmap) { if(pg->get_osdmap()->get_pg_size(pg->info.pgid.pgid) <= pg->actingset.size()) { if (pg->needs_recovery()) { // object in this PG cannot be found(need recovery) pg->state_set(PG_STATE_DEGRADED); } else { // all objects in PG recovered && actingset > local pg size pg->state_clear(PG_STATE_DEGRADED); } else { //PG->actingset.size() < pg->get_osdmap()->get_pg_size(pgid) pg->state_set(PG_STATE_DEGRADED); } } -
state_clear(PG_STATE_DEGRADED)
void PG::RecoveryState::Active::exit() { pg->state_clear(PG_STATE_DEGRADED); }//Started/Primary/Active/Recovered PG::RecoveryState::Recovered::Recovered(my_context ctx) { // if we finished backfill, all acting are active; recheck if // DEGRADED | UNDERSIZED is appropriate. if (pg->get_osdmap()->get_pg_size(pg->info.pgid.pgid) <= pg->actingbackfill.size()) { //acting sets after backfill pg->state_clear(PG_STATE_DEGRADED); pg->state_clear(PG_STATE_FORCED_BACKFILL| PG_STATE_FORCED_RECOVERY); } }
6. PG_STATE_RECOVERING
-
state_set(PG_STATE_RECOVERING)
//Started/Primary/Active/Recovering PG::RecoveryState::Recovering::Recovering(my_context ctx) { pg->state_clear(PG_STATE_RECOVERY_WAIT); pg->state_clear(PG_STATE_RECOVERY_TOOFULL); pg->state_set(PG_STATE_RECOVERING); } -
state_clear(PG_STATE_RECOVERING)
//called before peering void PG::start_peering_interval() { state_clear(PG_STATE_RECOVERING); }// when all replicas is recovered clear PG_STATE_RECOVERING boost::statechart::result PG::RecoveryState::Recovering::react(const AllReplicasRecovered &evt) { pg->state_clear(PG_STATE_RECOVERING); }
7. PG_STATE_BACKFILLING
-
state_set(PG_STATE_BACKFILLING)
PG::RecoveryState::Backfilling::Backfilling(my_context ctx) { pg->state_set(PG_STATE_BACKFILLING); } -
state_clear(PG_STATE_BACKFILLING)
bool PrimaryLogPG::start_recovery_ops() { state_clear(PG_STATE_BACKFILLING); }
8. PG_STATE_REMAPPED
REMAPPED means the up set is not equals to acting set. More specific, a new OSD join the cluster. PG is temporarily mapped to a different set of OSDs from what CRUSH specified. So PG_STATE_REMAPPED is set.
-
state_set(PG_STATE_REMAPPED)
-
state_clear(PG_STATE_REMAPPED)
/* Called before initializing peering during advance_map */ void PG::start_peering_interval() { // This will now be remapped during a backfill in cases // that it would not have been before. if (up != acting) state_set(PG_STATE_REMAPPED); else state_clear(PG_STATE_REMAPPED); }
9. PG_STATE_STALE
If the Primary OSD of a placement group’s acting set fails to report to the monitor or if other OSDs have reported the primary OSD down, the monitors will mark the placement group stale.
This state is set by monitor not by the PG itself.
void PGMonitor::on_active()
{
if (mon->is_leader()) {
check_osd_map(mon->osdmon()->osdmap.epoch);
}
}
void PGMonitor::check_osd_map(epoch_t epoch)
{
check_down_pgs();
}
void PGMonitor::check_down_pgs()
{
for (auto p : pg_map.pg_stat) {
////is primary but is down
if ((p.second.state & PG_STATE_STALE) == 0 &&
p.second.acting_primary != -1 &&
osdmap->is_down(p.second.acting_primary)) {
_try_mark_pg_stale(osdmap.get(), p.first, p.second);
}
}
}
void PGMonitor::_try_mark_pg_stale()
{
tat->state |= PG_STATE_STALE;
}
###Reference