RAFT论文 Leader Election & Log Replication
1, Basic Concept
Raft LOG
Raft的log 实际上是当前节点看待请求的先后顺序。只要保证所有节点的log 一致的,就能保证所有节点对于请求先后的一致性。log 当中包含当前请求的term 和 index,只要这一条 log 被commit了,这一条log 就应该保留下来,即使切主发生(chapter 5.4)。
Term and index
Term 的概念是类似于纪元的概念,只要需要重新选举,这个term就会自增,并且节点会用自增的term来区别这一次请求是本纪元(集群变动之后)的请求,还是上一纪元的请求。根据raft的算法,节点不会接受来自于之前纪元的请求。(chapter 5.1)
Index 是每一次请求的编号。为了避免同一条命令多次重复执行,raft 为每一次请求创建一个编号,如果收到已经执行了的index,节点并不会重复执行。(chaper 8)
Commit and Apply
Commit:认知到此条log已经被复制到大多数节点上,这条log 才是committed。此时这条log 可以被apply 到state machine 中。
A log entry is committed once the leader that created the entry has replicated it on a majority of the servers.
Apply: 此条log被应用到state machine中,这条log 是被applied。个人理解apply log的过程就是这条log被持久化的过程。
2,Leader Election
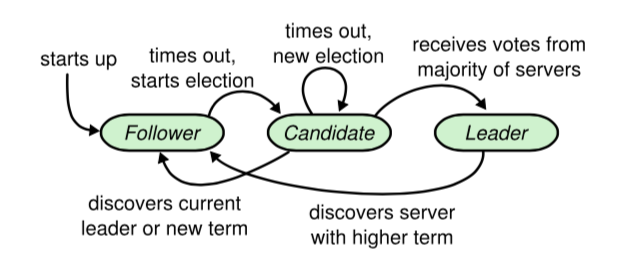
选主的过程逻辑相对简单。如果follow 自己的timer过期,节点自己会发送RequestVote RPC进行选举,如果收到了大多数的选票支持,这个节点自然成为leader。如果在timer内没有收到半数选举,就在一个新的term中重新进行下一轮的选举。值得注意的是raft规定(chaper 5.1),无论任何时候收到了请求中term 比current_term 大。该节点更新自己的current_term并且变为follower。
如何定义定义Up-to-date?
Raft 定义如果收到的RequestVote RPC显示sender的log比自己更Up-to-date, 就投该节点一票。那么如何定义Up-to-date呢?
Raft determines which of two logs is more up-to-date by comparing the index and term of the last entries in the log.If the logs have last entries with different terms, then the log with the later term is more up-to-date. If the logs end with the same term, then whichever log is longer is more up-to-date.
raft 比较log中的term 谁大谁就更Up-to-date。如果term一样,谁更新谁就更Up-to-date。注意这里比较的是当前log中的term,并不是current_term。
至此leader election就结束了。
3,Log Replication
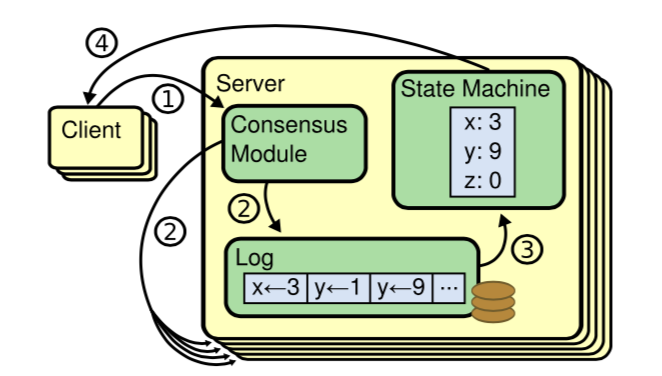
Leader election结束后,leader 会在自己的term中不停的向从发送log (AppendEntries RPC),在收到多数follower 收到这条log之后,就可以写入到State Machine中,之后返回客户端。
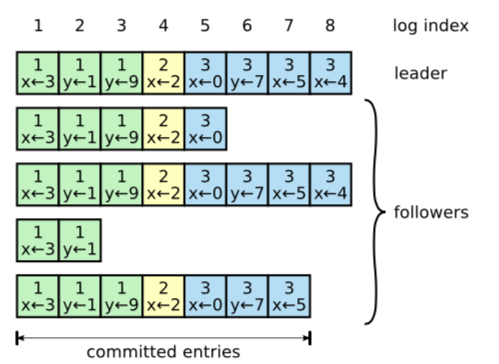
Follower Log
相比于上述状态机描述的场景,实际的情况要复杂的多,follower如何能放心的写下当前log 并且确保这条log之前所有的log 都跟主一样呢?
Raft 论文中列举出了follower log的几种情况。

从上图中可以看出,由于频繁的网络割接和节点故障。最终的follower本地log会比较复杂。
如何处理follower log 与leader log 不一致?
Raft log 复制机制就是为了保障follower 上的committed log 一定会跟leader上完全一致。实际上由于Leader Append-Only性质,leader 是不会回退log的,raft的复制机制将leader上的log 完全复制到follower。上图中e,f 中slave中拥有 leader所没有的log,这种情况下需要follower进行相应的log回退,回退到follower的log在leader 中能找到的点位,然后从此点位继续同步log。
如何保证follower log 跟leader log 同步之后是一致的?
Raft 算法是在AppendEntries RPC 中带有当前同步log 上一条log 的term 和index,如果receiver 能在本地找到这一条prev_log,那么它将会接受当前log。反之通知leader 同步本条log失败,leader 会尝试发送之前的log。这样的机制保证了follower收到的每一条log N 的前提是收到了log N- 1,收到log N-1的前提是收到了 log N-2,以此类推结合Log Matching proprity,确保了follower的log 跟leader的log是完全一致的。
Leader 收到大多数follower的AppendEntries RPC反馈,就可以commit当前log。Raft 论文中讨论了一种特殊的情况。为了保证Leader Completeness的属性,Raft 永远不会commit 不属于自己term的log。
Raft never commits log entries from previous terms by counting replicas.
Raft 论文提出了一种场景如下:

在步骤c的时候,如果可以commit 不属于当前term的log ,那么term2 的黄色log 应该被commit,但是如果这个log被commit 之后,步骤d会覆盖这个黄色log,违背了Leader Completeness 性质,也就是committed log 丢失了。所以,反证法得知Raft 不应该commit 不属于自己term的log。
Term 2 log 什么时候是committed的呢?
Raft规定当前log 如果被commit,其之前的log都应该被commit。在步骤c中如果term 4的log被commit,如步骤e所示,由于term4的log 被commit,term 2 的log 就被commit了。
由于term4这条log被commit,说明这条log一定存在于过半数的follower上,这些过半数的follower上一定有leader这条log之前的所有log,这就说明新选出来的主一定是拥有term4 并且拥有term4之前的所有log(包括term2 log)。这就保证了term2 不会丢失。
当然如果步骤4中term4 的log被commit,按照raft算法步骤d是不可能出现的,因为s5持有的term3 并不会获得超过半数的投票。
至此,log replication 结束。
4,总结
总体来说,由于考虑网络异常,节点稳定性等因素,每一个节点的log 各不相同。对于leader election过程,主要工作是选出来一个最up-to-date的节点作为leader,这个过程主要是对up-to-date的概念的定义和理解。而log replicaiton的过程相对复杂,需要考虑每一种follower的log状态,目的是最终使其恢复到跟leader log 一样的状态。
5,Reference
In Search of an Understandable Consensus Algorithm
PacificA: Replication in Log-Based Distributed Storage Systems