Pika传火计划之主从同步

Introduction
Pika的主从同步的概念在经典模式下和集群模式下会有差异,但是其最基本的同步单元都是内部结构Partition的同步。Partition是Pika代码层面的最小同步单元,经典模式下多DB结构,每一个DB对应一个Partition,集群模式下每一个分片对应一个Partition,所以不管是什么模式,只是跳出Pika代码之外的概念有区别,在Pika代码内部统称为Partition的同步。下边主要关注经典模式下多DB的同步流程,集群模式下的同步感兴趣的同学可以自行整理。
Pika 的同步主要分为两个部分,首先是进程级别的同步,确认主从db个数是相同的。这一过程称之为MetaSync。之后每一个Partition单独同步,通过从给主发送的TrySync 信息,查看主从同步点位,从判断需要发起全量同步还是增量同步。全量同步由DbSync 消息来发起,增量同步由BinlogSync 消息来发起。需要注意的是全同步做完,从会再发送一次TrySync消息尝试BinlogSync来同步全同步期间的增量数据。
同步线程模型
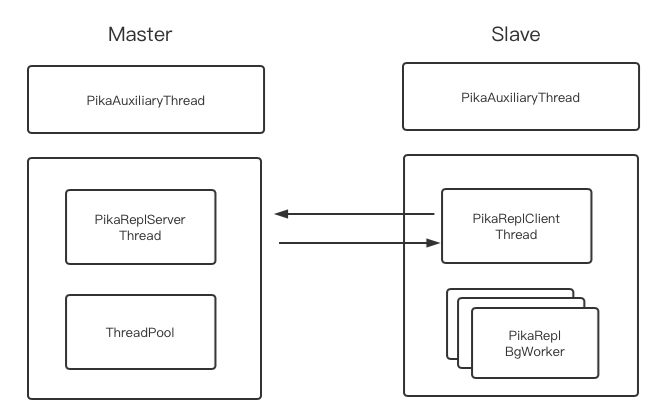
Pika的同步模型中,所有同步流程的发起者都是从节点(这一点很重要),MetaSync,TrySync,DbSync,BinlogSync都是从发起到主。在MetaSync,TrySync,DbSync,BinlogSync流程中,主的回复用的连接是从发起请求时建立的连接。即上图中主PikaReplServerThread 到 PikaReplClientThread 的连接。
class PikaAuxiliaryThread : public pink::Thread {
virtual void* ThreadMain();
while (!should_stop()) {
if (g_pika_server->ShouldMetaSync()) {
g_pika_rm->SendMetaSyncRequest();
} else if (g_pika_server->MetaSyncDone()) {
g_pika_rm->RunSyncSlavePartitionStateMachine();
}
Status s = g_pika_rm->CheckSyncTimeout(slash::NowMicros());
s = g_pika_server->TriggerSendBinlogSync();
int res = g_pika_server->SendToPeer();
if (!res) {
// sleep 100 ms
mu_.Lock();
cv_.TimedWait(100);
mu_.Unlock();
}
}
}
辅助线程的工作主要包括1)Pika同步MetaSync消息发送,2)TrySync消息发送,3)驱动BinlogSync流程启动,4)Partition级别的keepalive和超时检测。
其中,SendToPeer函数负责尝试向从发送消息,返回值代表发送了多少条Binlog,如果没有任何可以发送的Binlog,为了让出CPU资源,辅助线程会sleep 100ms。
class PikaReplClient {
PikaReplClientThread* client_thread_;
std::vector<PikaReplBgWorker*> bg_workers_;
Status SendMetaSync();
Status SendPartitionDBSync(...);
Status SendPartitionTrySync((...);
Status SendPartitionBinlogSync(...);
};
class PikaReplClientThread : public pink::ClientThread {
class ReplClientConnFactory : public pink::ConnFactory {
virtual std::shared_ptr<pink::PinkConn> NewPinkConn(...) {
return std::make_shared<PikaReplClientConn>(...);
}
}
class ReplClientHandle : public pink::ClientHandle {
void FdTimeoutHandle(int fd, const std::string& ip_port) const override;
void FdClosedHandle(int fd, const std::string& ip_port) const override;
}
}
class PikaReplClientConn: public pink::PbConn {
int DealMessage() override;
static void HandleMetaSyncResponse(void* arg);
static void HandleDBSyncResponse(void* arg);
static void HandleTrySyncResponse(void* arg);
void DispatchBinlogRes(
const std::shared_ptr<InnerMessage::InnerResponse> response);
}
class PikaReplBgWorker {
pink::BGThread bg_thread_;
static void HandleBGWorkerWriteBinlog(void* arg);
static void HandleBGWorkerWriteDB(void* arg);
}
class PikaReplClient 中包含了PikaReplClientThread 异步客户端,和一组PikaReplBgWorker异步处理binlog的读写。并且PikaReplClient中封装了各个协议的Send函数。
1,PikaReplClientThread继承自ClientThread,其本质是一个异步的客户端 ,定义了ReplClientConnFactory和ReplClientHandle。ConnFactory 和ClientHandle 的含义详见Pika传火计划之线程模型。
2,PikaReplClientConn继承自PbConn,其通信协议为Protobuf协议,其中包含了PikaReplClientThread接收到相应协议的处理函数。
3,PikaReplBgWorker是高效处理同步过来Binlog的一组工作线程。PikaReplClientThread接收到相应协议报文后,对于一些阻塞的操作,例如本地Binlog写入和Db的写入等操作会直接安排给PikaReplBgWorker 操作。避免阻塞PikaReplClientThread后续报文的处理。
class PikaReplServer {
// thread pool size PIKA_REPL_SERVER_TP_SIZE 3
pink::ThreadPool* server_tp_;
PikaReplServerThread* pika_repl_server_thread_;
slash::Status SendSlaveBinlogChips(
const std::string& ip,
int port, const std::vector<WriteTask>& tasks);
void Schedule(pink::TaskFunc func, void* arg);
}
class PikaReplServerThread : public pink::HolyThread {
class ReplServerConnFactory : public pink::ConnFactory {
virtual std::shared_ptr<pink::PinkConn> NewPinkConn(...) {
return std::make_shared<PikaReplServerConn>(...);
}
}
class ReplServerHandle : public pink::ServerHandle {
virtual void FdClosedHandle(
int fd, const std::string& ip_port) const override;
}
}
class PikaReplServerConn: public pink::PbConn {
int DealMessage();
static void HandleMetaSyncRequest(void* arg);
static void HandleTrySyncRequest(void* arg);
static void HandleDBSyncRequest(void* arg);
static void HandleBinlogSyncRequest(void* arg);
}
class PikaReplServer 包含了一个小型线程池ThreadPool,和PikaReplServerThread。并且包含了发送Binlog的接口SendSlaveBinlogChips。
1,PikaReplServerThread继承自HolyThread,HolyThread继承自ServerThread,实现了HandleConnEvent和HandleNewConn,是一个单线程的轻量级server。同时也实现了ReplServerConnFactory 和ReplServerHandle。
2,PikaReplServerConn 继承自PbConn,其通信协议也是Protobuf协议。其中还包含了PikaReplServerThread接收到相应协议的处理函数。
3,由于PikaReplServerThread 由于收到Binlog的ack之后会从磁盘中加载下次同步到从的binlog到内存中,所以为了避免阻塞PikaReplServerThread后续报文处理,会阻塞的操作被安排到了ThreadPool 当中。
主从协商建立同步
主从建立同步的过程分为MetaSync=>TrySync=>BinlogSync,或者MetaSync=>TrySync=>DbSync=>BinlogSync两种模式。MetaSync 是进程之间的主从同步db个数是否一样。TrySync是每一个从Partition主动发起,将自己Binlog的位置发送给主,接收到主的返回TrySyncResp之后,进一步判断是全量同步做DbSync 还是直接可以增量同步做BinlogSync。
MetaSync
在正式建立同步之前需要对于主从进程的的db个数进行确认,这一过程称之为MetaSync。
其交互过程如下。
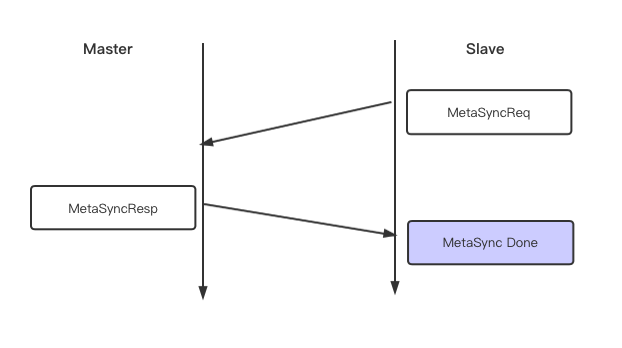
void PikaReplServerConn::HandleMetaSyncRequest(void* arg) {
// build server table meta info
...;
// use same conn write back
conn->WriteResp(reply_str);
conn->NotifyWrite();
}
void PikaReplClientConn::HandleMetaSyncResponse(void* arg) {
// check if table is the same as master's
if (!PikaReplClientConn::IsTableStructConsistent(...))) {
g_pika_server->SyncError();
conn->NotifyClose();
}
g_pika_server->FinishMetaSync();
}
TrySync
MetaSync之后,每一个Partition单独做TrySync,从的Partition 带着自己当前的同步点位向主做请求。主根据从的TrySync消息,如果本地有从发送过来的点位,则回复建议进行增量同步走BinlogSync流程,如果没有,则回复建议进行全量同步走DbSync流程。
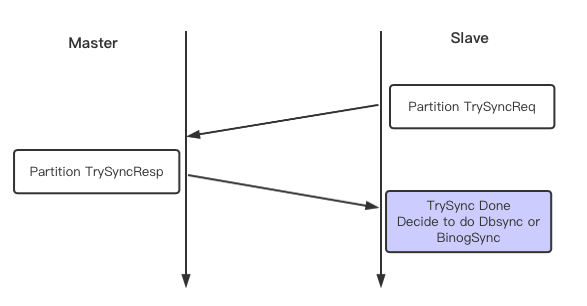
void PikaReplServerConn::HandleTrySyncRequest(void* arg) {
// master check if slave offset is valid
...;
// master check if this slave is already exist
if (!partition->CheckSlaveNodeExist(node.ip(), node.port())) {
int32_t session_id = partition->GenSessionId();
try_sync_response->set_session_id(session_id);
Status s = partition->AddSlaveNode(node.ip(), node.port(), session_id);
} else {
Status s = partition->GetSlaveNodeSession(
node.ip(), node.port(), &session_id);
try_sync_response->set_session_id(session_id);
}
onn->WriteResp(reply_str);
conn->NotifyWrite();
}
void PikaReplClientConn::HandleTrySyncResponse(void* arg) {
if (try_sync_response.reply_code()
== InnerMessage::InnerResponse::TrySync::kOk) {
slave_partition->SetMasterSessionId(session_id);
g_pika_rm->SendPartitionBinlogSyncAckRequest(
table_name, partition_id, offset, offset, true);
slave_partition->SetReplState(ReplState::kConnected);
} else if (try_sync_response.reply_code() == kSyncPointBePurged) {
// Need To Try DBSync
slave_partition->SetReplState(ReplState::kTryDBSync);
} else if (try_sync_response.reply_code() == kSyncPointLarger) {
// rySync Error, Because the invalid filenum and offset
slave_partition->SetReplState(ReplState::kError);
} else if (try_sync_response.reply_code() == kError) {
slave_partition->SetReplState(ReplState::kError);
}
}
从节点接收到TrySyncResponse之后
1,(kOk) 如果从返回没有问题,则进行增量同步,发送BinlogSync消息。
2,(kSyncPointBePurged)如果自己的同步点位,在主节点已经被清除。则进行全量同步,发送DbSync 消息。
3,(kSyncPointLarger)如果从点位比主超前,说明从上的数据有一部分是脏数据,将同步终止(kError),需要管理员介入。
4,(kError)如果主返回的TrySyncResponse 有异常,那么将同步终止(kError),需要管理员介入。
DbSync
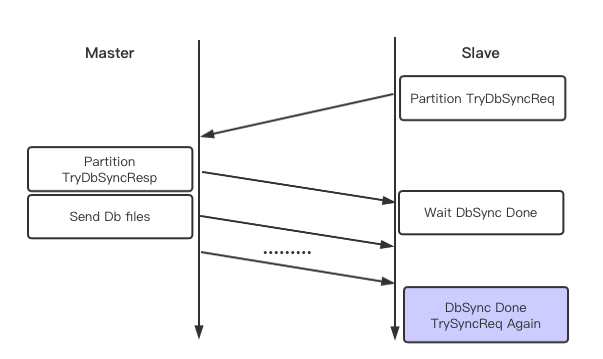
Pika全量同步,主要依赖于RSYNC工具,通过system调用起RSYNC进程,将主上数据推到从上。目前从上一直起一个RSYNC常驻进程,专门负责接收主同步过来的全同步数据。
Master DbSync Behavior
void PikaReplServerConn::HandleDBSyncRequest(void* arg) {
// sanity check
...;
g_pika_server->TryDBSync(node.ip(), node.port() + kPortShiftRSync,
table_name, partition_id);
conn->WriteResp(reply_str);
conn->NotifyWrite();
}
void PikaServer::TryDBSync(const std::string& ip, int port,
const std::string& table_name,
uint32_t partition_id) {
partition->BgSavePartition();
DBSync(ip, port, table_name, partition_id);
}
主收到HandleDBSyncRequest
1,调用TryDBSync的BgSavePartition,异步将对应的partition打快照。
2,调用DBSync 异步发送。
为保证打快照和发送的文件的先后循序,这两个任务由同一个线程完成。这个线程会根据放入其消费队列的顺序依次执行任务。这里一定是先执行打快照任务,再执行发送文件任务。
void Partition::BgSavePartition() {
slash::MutexLock l(&bgsave_protector_);
if (bgsave_info_.bgsaving) {
return;
}
bgsave_info_.bgsaving = true;
BgTaskArg* bg_task_arg = new BgTaskArg();
bg_task_arg->partition = shared_from_this();
g_pika_server->BGSaveTaskSchedule(
&DoBgSave, static_cast<void*>(bg_task_arg));
}
void PikaServer::BGSaveTaskSchedule(pink::TaskFunc func, void* arg) {
bgsave_thread_.StartThread();
bgsave_thread_.Schedule(func, arg);
}
void Partition::DoBgSave(void* arg) {
// do bgsave https://github.com/Qihoo360/pika/wiki/pika-快照式备份方案
// generate a info file indicate this snapshot's binlog filenum and offset
}
1,调用BGSaveTaskSchedule将打快照任务放入bgsave_thread的消费队列中。
2,bgsave_thread调用DoBgSave 对当前的DB状态打快照并且生成info文件,info文件是代表这个快照对应的binlog filenum和offset 的位置。
void PikaServer::DBSync(const std::string& ip, int port,
const std::string& table_name,
uint32_t partition_id) {
// check if this partition_is is processing dbsync
...;
// Reuse the bgsave_thread_
// Since we expect BgSave and DBSync execute serially
bgsave_thread_.Schedule(&DoDBSync, reinterpret_cast<void*>(arg));
}
// DoDBSync
void PikaServer::DbSyncSendFile(const std::string& ip, int port,
const std::string& table_name,
uint32_t partition_id) {
// sending files
...;
// Send info file at last
...;
}
1, 调用DBSync 将发送文件的任务放入bgsave_thread的消费队列中。
2,bgsave_thread调用DbSyncSendFile,依次发送快照的文件。最后发送info文件。
Slave DbSync Behavior
void PikaReplClientConn::HandleDBSyncResponse(void* arg) {
slave_partition->SetReplState(ReplState::kWaitDBSync);
}
// PikaAuxiliaryThread invoke this periodically
Status PikaReplicaManager::RunSyncSlavePartitionStateMachine() {
if (s_partition->State() == ReplState::kWaitDBSync) {
rtition->TryUpdateMasterOffset();
}
}
bool Partition::TryUpdateMasterOffset() {
// 1, Check dbsync finished, got the new binlog offset from info file
// 2, Replace the old db
// 3, Update master offset, and TrySync again
}
1,从收到DBSyncResponse 将partition置为kWaitDBSync。
2,辅助线程PikaAuxiliaryThread 周期性检查DbSync 有没有结束,结束的标志为在本地检测到Info文件的存在。
3,如果DbSync 检测完,解析info文件的filenum offset,替换本地的Db,本地替换成新的filenum和offset,并且重走TrySync流程,同步DbSync期间产生的增量。
BinlogSync
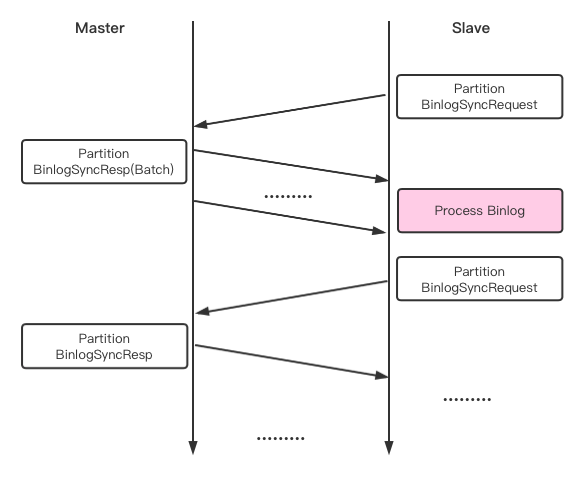
BinlogSync的同步逻辑,也是从发起的。
1,从先发送一个BinlogSyncRequest,其中有一个first_send标志,第一次发送设置first_send为True。
2,主上收到BinlogSyncRequest看到first_send为true,则会相应做一些初始化工作,之后将待发送数据写入RM::write_queues中。然后由辅助线程用之前从创建的连接发送write_queues中的Binlog数据。
3,从接到Binlog数据后,返回相应的BinlogSyncAck消息(复用BinlogSyncRequest结构)。
4,主收到BinlogSyncAck会,继续将后续带发送数据再写入write_queues 由辅助线程发送到从。
需要注意的是以下两种场景:
1,当主从数据完全一致,并且过了很久没有同步数据的时候,辅助线程会为了保持连接的keepalive,会每隔kSendKeepAliveTimeout 向这条连接发送keealive消息。并且检查主的last_recv_time,如果超过kRecvKeepAliveTimeout没有收到任何消息,则主动将连接断开。
2,由于从是BinlogSync的发起者,但是一段时间没有数据同步之后,从感知不到主上新的数据写入,从而不能再主动再次发起BinlogSync 流程,这时候需要辅助线程来调用TriggerSendBinlogSync,驱动BinlogSync流程。TriggerSendBinlogSync的主要逻辑就是将新写入的增量放入write_queues,再发送给从。
void PikaReplServerConn::HandleBinlogSyncRequest(void* arg) {
if (is_first_send) {
master_partition->ActivateSlaveBinlogSync(
node.ip(), node.port(), range_start);
return;
}
// read next sync binlog to write_queues
s = g_pika_rm->UpdateSyncBinlogStatus(slave_node, range_start, range_end);
}
1,主收到从的BinlogSyncRequest后,如果是第一次发送,则初始化本地的一些参数。
2,主把下一次同步的消息放入write_queues 中。具体主将哪些的Binlog 放入write_queues,参考增量同步滑动窗口设计。
void PikaReplClientConn::DispatchBinlogRes(
const std::shared_ptr<InnerMessage::InnerResponse> res) {
g_pika_rm->ScheduleWriteBinlogTask(
table_name_ + partition_id_, res, PikaReplClientConn));
}
void PikaReplBgWorker::HandleBGWorkerWriteBinlog(void* arg) {
for (InnerResponse binlogs) {
redis_parser_.ProcessInputBuffer(
redis_parser_start, redis_parser_len, &processed_len);
}
g_pika_rm->SendPartitionBinlogSyncAckRequest(
table_name, partition_id, ack_start, ack_end);
}
int PikaReplBgWorker::HandleWriteBinlog(
pink::RedisParser* parser, const pink::RedisCmdArgsType& argv) {
c_ptr->Initial(argv, worker->table_name_);
partition->ConsensusProcessLeaderLog(c_ptr, worker->binlog_item_);
}
Status ConsensusCoordinator::ProcessLeaderLog(
std::shared_ptr<Cmd> cmd_ptr, const BinlogItem& attribute) {
Status s = InternalAppendLog(attribute, cmd_ptr, nullptr, nullptr);
// do g_pika_rm->ScheduleWriteDBTask(); in InternalApplyFollower
InternalApplyFollower(
MemLog::LogItem(LogOffset(), cmd_ptr, nullptr, nullptr));
}
void PikaReplBgWorker::HandleBGWorkerWriteDB(void* arg) {
c_ptr->Do(partition);
}
从收到主发送的Binlog信息之后
1,调用DispatchBinlogRes,为保证相同partition的binlog 写入顺序,将同talbe_name同partition_id的binlog处理流程安排给同一个线程。
2,PikaReplBgWorker线程调用HandleBGWorkerWriteBinlog,将binlog放入redis_parser中,redis_parser解析出完整的命令后调用HandleWriteBinlog。
3,调用ConsensusProcessLeaderLog=>ProcessLeaderLog,通过InternalAppendLog 写入Binlog,通过InternalApplyFollower调用,ScheduleWriteDBTask。
4,返回步骤2,在写完Binlog之后发送BinlogSyncAckRequest进行下一次BinlogSync。
5,在步骤3中,ScheduleWriteDBTask 之后,PikaReplBgWorker线程调用HandleBGWorkerWriteDB 将数据落盘。
一致性同步
通过之前的介绍,主从之间的同步使用了Protobuf协议,在使用一致性版本的pika的时候,在Pb协议中添加了ConsensusMeta。通过解析Pb填充的ConsensusMeta的数据,进行一致性下的主从通信。其Pb协议中定义如下。在TrySync和BinlogSync的逻辑中通过判断Pb报文中是否携带ConsensusMeta 来判断对端是否开启一致性功能。
message ConsensusMeta {
optional uint32 term = 1;
// Leader -> Follower prev_log_offset
// Follower -> Leader last_log_offset
optional BinlogOffset log_offset = 2;
optional BinlogOffset commit = 3;
optional bool reject = 4;
repeated BinlogOffset hint = 5;
}
其主要设计见副本一致性设计文档。
从在一致性场景下的数据写入
void PikaReplBgWorker::HandleBGWorkerWriteBinlog(void* arg) {
for (InnerResponse binlogs) {
HandleWriteBinlog();
}
if (res->has_consensus_meta()) {
partition->ConsensusProcessLocalUpdate(leader_commit);
}
...;
}
PikaReplBgWorker::HandleWriteBinlog(
pink::RedisParser* parser, const pink::RedisCmdArgsType& argv) {
c_ptr->Initial(argv, worker->table_name_);
partition->ConsensusProcessLeaderLog(c_ptr, worker->binlog_item_);
}
1, 一致性场景下,在PikaReplBgWorker处理主同步过来的Binlog 同样调用了ConsensusProcessLeaderLog接口,写入Binlog。
2,在HandleBGWorkerWriteBinlog函数调用的最后,调用ConsensusProcessLocalUpdate 接口,更新从的commit信息,调用ScheduleApplyFollowerLog 将从可以写入DB的请求异步写入DB。
主在一致性场景下的数据写入
void PikaReplServerConn::HandleBinlogSyncRequest(void* arg) {
s = g_pika_rm->UpdateSyncBinlogStatus(slave_node, range_start, range_end);
}
Status ConsensusCoordinator::UpdateSlave(const std::string& ip, int port,
const LogOffset& start, const LogOffset& end) {
LogOffset committed_index;
// invoke InternalCalCommittedIndex to calculate committed_index
Status s = sync_pros_.Update(ip, port, start, end, &committed_index);
if (!s.ok()) {
return s;
}
LogOffset updated_committed_index;
bool need_update = false;
{
slash::MutexLock l(&index_mu_);
need_update = InternalUpdateCommittedIndex(
committed_index, &updated_committed_index);
}
if (need_update) {
// sheduel DoExecTask
s = ScheduleApplyLog(updated_committed_index);
if (!s.ok() && !s.IsNotFound()) {
return s;
}
}
return Status::OK();
}
1,HandleBinlogSyncRequest => UpdateSyncBinlogStatus => ConsensusUpdateSlave => UpdateSlave
2,UpdateSlave函数中调用sync_pros.Update更新对应的从节点的acked_offset,同时更新这个从的match_index,代表已经同步到该从的最高的LogOffset。然后依据match_index数组计算主上的committed_index。
3,更新主的committed_index。
4,如果成功更新committed_index,进而schedule应用log,每一条可以应用的log调用回调DoExecTask完成对DB的写入。