Innodb Undo Purge and Truncate

Undo 的主要作用是保留修改之前的数据,这些数据用在MVCC, rollback, recovery 等流程当中。但是undo record 的数据不可能永久存在,所以需要在适当的情况下做 undo 的purge 和truncate。Undo purge 操作主要是清除已经删除的主键索引跟二级索引,主要针对于用户record 级别的操作。undo truncate 操作主要是针对undo space 本身的操作,例如undo rollback segment 本身的数据清理,例如undo space 整体的重建。
1,Undo Purge
purge 的流程主要是由两部分组成,首先是扫描出来需要purge 的undo record。这个流程在srv_purge_coordinator_thread 内部实现。之后是purge worker thread对于这些undo record 进行真正的数据清理。
整体的undo purge 流程由srv_purge_coordinator_thread 控制, 通过控制purge 的线程个数(srv_n_purge_threads)跟一个batch 具体purge 多少undo page (srv_purge_batch_size)来控制purge 的力度。之后把扫描出来的undo record 分派给purge work thread。分派的时候按照undo record 需要操作的table id 聚合,操作同一个table id 的undo record 尽量分配给一个purge worker thread 。这样可以减少一部分锁竞争。
srv_purge_coordinator_thread => srv_do_purge =>trx_purge
ulint trx_purge() {
trx_sys->mvcc->clone_oldest_view(&purge_sys->view);
// Step1 扫描这次需要purge 的undo record
trx_purge_attach_undo_recs();
/* Submit the tasks to the work queue. */
for (ulint i = 0; i < n_purge_threads - 1; ++i) {
// Step 2 将purge 的task 提交到srv_sys->tasks 当中,
// srv_worker_thread 会读取srv_sys->tasks 的任务依次执行
srv_que_task_enqueue_low(thr);
}
// 等待所有的purge 线程做完任务
trx_purge_wait_for_workers_to_complete();
// Step3 做undo truncate
trx_purge_truncate();
}
1.1,扫出需要pruge 的undo record(trx_purge_attach_undo_recs)
需要purge 哪些undo 内核中由purge system 控制,主要实现在 trx_purge_attach_undo_recs 当中。主要流程是把history list 上面的undo recrod 依次摘下。
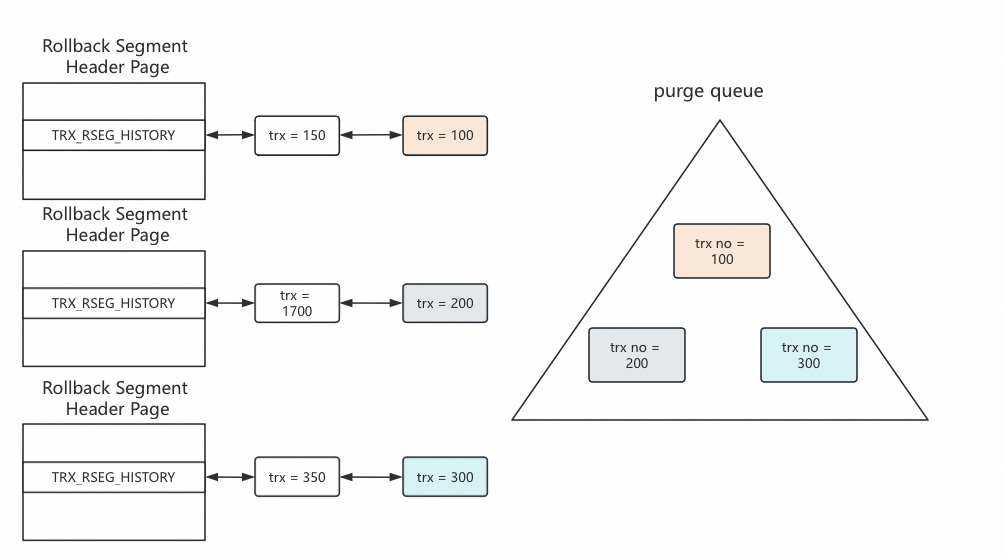
Undo spaces上面有若干个 rollback segment, 每个rollback segment 上面又有一个持久化的list 叫TRX_RSEG_HISTORY(history list),事务在commit 的时候头插到这个history list 上面。
同时维护内存的 purge_sys->purge_queue ,这是个最小堆,内部维护每个rollback segment 的history list 上面最老事务的undo record。这样可以pop出来全局最小的trx no 的事务,整体按照trx no从小到大的顺序进行 purge。
如下图所示,purge_queue 的初始化是在实例启动时候检查rollback segment 有没有要purge 的事务,如果有,这个rollback segment 的最老的事务就加入到purge queue 当中。purge 流程开始后,purge queue 首先pop 出来trx no =100的事务产生的undo,之后对这个事务的所有undo record 进行扫描,trx no=100 扫描完,会把这个rollback segment 的最小事务也就是trx no =150 的事务放到purge queue 最小堆里面,再次pop 的时候trx no=150 的事务会再次被pop 出来进行处理,这样来达到一直处理当前全局最小trx no的事务的目的。
具体对于每一个trx 产生的undo record 的组织形式见: INNODB_UNDO_PHYSICAL_FORMAT
对应的函数实现见 trx_purge_attach_undo_recs->trx_purge_fetch_next_rec
static trx_undo_rec_t* trx_purge_fetch_next_rec()
|->trx_undo_build_roll_ptr();
|-> trx_purge_get_next_rec(n_pages_handled, heap));
|-> trx_undo_page_get_next_rec() // 读取一个page 里面的下一条record
|-> trx_undo_get_next_rec_from_next_page() // 切换这个undo segment 里面的下一个page
|-> trx_purge_rseg_get_next_history_log() // 切换histlist 上的node (下一个trx 产生的undo)进入purge queue
|-> trx_purge_choose_next_log() // 从purge_queue上选择下一个要purge 的rseg 上的事务产生的undo(这是个最小堆),
//选出全局最小的下一个要purge 的事务
|-> trx_purge_read_undo_rec() // 更新purge_sys内部参数
哪些undo record 可以被pruge?
innodb 当中的解释是这样的:
// 扫描过程当中trx_purge_fetch_next_rec返回null ,就代表没有什么undo 可以purge 了
trx_undo_rec_t* trx_purge_fetch_next_rec() {
if (purge_sys->iter.trx_no >= purge_sys->view.low_limit_no()) {
return (NULL);
}
...
}
purge 的时候需要取到所有的read view 当中的最老的一个view,比较history list 的trx no 跟这个view 的m_low_limit_no,如果historylist 拿到的trx no 小于m_low_limit_no,可以被purge。(ReadView::m_low_limit_no 这个值是MVCC::view_open 的时候调用ReadView::prepare 取trx_sys->serialisation_min_trx_no 赋值的。也就是view 生成的时候对应的当前serialisation list 里面最小的trx no。serialisation list 里面的值是正在commit 的一些事务,取这个list 的最小值可以保证这个trx no 之前的事务都已经提交结束。)因为已经commit 事务的undo 是记录这个事务之前一个版本的数据,undo record 的trx id 和内容是上一次修改的内容,如果最老的view 开启的时候都是在这个undo trx no 提交之后,那么这个最老的view 以及之后的所有view,应该看到这个版本之前更新的版本,都不需要看这个record 更老的版本了,那么这个undo record 对应的这个版本就可以purge 掉了。
例如:
oldest view(purge view) ( [10, 25,27,28] high id=50, m_low_limit_no=40)
Historylist 上面有一个trx_no = 20 trx_id = 5 的事务(TRX_UNDO_TRX_ID = 5, TRX_UNDO_TRX_NO=20)。内部的undo record 有一条是update ,undo record 解析出来 trx_id = 2 , 代表这个undo record是trx_id = 2 产生的数据。这一条的undo可以被删除。
具体的这个 record 的版本链路应该是
[trx_id=1000(盘上)] ->(rollptr)-> [trx_id = 40] -> [trx_id=5] -> [trx_id = 2]
purge操作删除了trx_id= 2 的 record 这个版本,最老的view 还是能沿着版本链找到trx_id = 5 对应的record 的。
至此需要purge 的undo record 已经被被扫出来了。下一步就是purge worker thread 真正对这些undo record 进行清理。
1.2, 执行具体的undo record purge(row_purge)
通过trx_purge 函数扫描出来的undo record 被分发到若干(n_purge_threads)purge work thread 上面,purge worker thread 的 入口函数是row_purge,主要流程是对于这些undo record 进行解析,然后根据不同的undo 类型分别进行数据清理。解析的流程见row_purge_parse_undo_rec,主要是把undo record 字段解析成内存字段。之后调用row_purge_record 对于TRX_UNDO_DEL_MARK_REC 类型跟TRX_UNDO_UPD_EXIST_REC 类型分别进行处理。
/** parse undo rec */
static bool row_purge_parse_undo_rec() {
trx_undo_rec_get_pars();/*parse type, cmpl_info, if_updated_extern, undo_no, table_id */
trx_undo_update_rec_get_sys_cols(); /*parse info_bits, trx_is, roll_ptr */
trx_undo_rec_get_row_ref(); /* 解析这条undo record的主键字段 */
trx_undo_update_rec_get_update(); /* 把redo record 的更新字段parse 到upd_t 里面, 按照<field_no,len, data>的顺序*/
}
// do actual work
static bool row_purge_record() {
// delete 标记删除之后,这里做真正的删除,包括主键索引和可能的二级索引
case TRX_UNDO_DEL_MARK_REC:
purged = row_purge_del_mark(node);
// update 需要删除可能的二级索引和可能的外部存储
case TRX_UNDO_UPD_EXIST_REC:
row_purge_upd_exist_or_extern(thr, node, undo_rec);
}
TRX_UNDO_DEL_MARK_REC 类型
对于TRX_UNDO_DEL_MARK_REC 类型,首先需要删除这个主键索引对应的所有二级索引,之后再物理上删除主键索引。
删除二级索引的流程比较特殊,这里先用主键索引构建二级索引的字段。之后再去删除二级索引上面的对应这个版本的record。但是由于二级索引上面没有trx id 这个字段,没办法知道读到的二级索引是哪个trx 写入的。所以需要遍历主键的版本,如果这个二级索引对应的某一个版本主键还有人能够看到,那么这个二级索引就不应该被删除。(由于二级索引是没有版本的,只能通过对应字段的相同来判断对应的是哪个主键。)
static bool row_purge_del_mark() {
//1, 删除所有可能的二级索引,进到这里的node->index全是二级索引了。
row_build_index_entry_low(); // 从主键索引的dtuple 拷贝构建二级索引的dtuple
row_purge_remove_sec_if_poss();
->row_search_index_entry; // btr_pcur_open(PAGE_CUR_LE)
->row_purge_poss_sec // 查看这个二级索引是否能被删除
->row_vers_old_has_index_entry
// 如果有lob 类型会相应的在btr_cur_pessimistic_delete 内部调用 free_externally_stored_fields 进行删除
-> btr_cur_optimistic_delete/btr_cur_pessimistic_delete
//2, 删除主键索引
row_purge_remove_clust_if_poss();
}
// 查找有没有一个主键索引对应的二级索引就是这个要删除的二级索引。如果有,这个二级索引就不能被删除。
// 这里查询主键索引的原因还是二级索引本身是没有trx id 的,需要回查主键索引来确定二级索引能否被删除。
ibool row_vers_old_has_index_entry() {
// 1,查找btree 上面最新的版本主键record,如果没有被删除,并且跟二级索引上边的field 都一致,那么这个二级索引, 有一个并不准备删除的主键索引。
// 2,查找之前的版本,如果有有一个版本的主键record 没有被删除并且跟二级索引上边的field 都一致,那么这个二级索引, 有一个并不准备删除的主键索引。
// 对于undo purge del mark 的流程,以上两种情况这个二级索引不能被删除。
// 2中查找之前的版本的时候调用 trx_undo_prev_version_build 这里调用trx_undo_get_undo_rec=>purge_sys->view.changes_visible.
// 发现purge view 能看到这个版本的record就结束向上构建历史版本,因为purge view 能看到这个版本说明其他的view 至少应该看见这个版本
// 所以这个版本之前的版本就一定没有人看了,之前的版本就应该是可以被purge 但是还没有purge 到的版本。
}
TRX_UNDO_UPD_EXIST_REC 类型
对于TRX_UNDO_UPD_EXIST_REC,首先需要删除修改字段对应的二级索引,其次对于blob 类型update 操作,老数据也是存储在相同的btree 里面的,这里需要一起删除掉老版本的blob。
static void row_purge_upd_exist_or_extern() {
// 删除update 产生的二级索引的修改
// 删除老数据的blob 数据版本, blob 的update 。
}
TRX_UNDO_INSERT_REC 类型
insert 类型由于没有需要处理的之前版本的数据, 是不需要undo purge 处理的。
TRX_UNDO_UPD_DEL_REC 类型
为什么TRX_UNDO_UPD_DEL_REC 类型的undo 不用purge 呢?
TRX_UNDO_UPD_DEL_REC 类型产生的场景是本身这个主键索引由于用户删除标记了delete mark,但是还没有来得及purge,这时候用户层面insert 了一条相同主键的record。这时候TRX_UNDO_UPD_DEL_REC 类型对应的主键操作是,把delete mark 消掉,如果修改了二级索引的字段,就把原来的二级索引删除(应该已经标记删除了),再插入一个新的二级索引。如果没有修改之前的二级索引,就把之前的二级索引的delete mark 消掉。所以本质上类似于insert 操作,没有产生任何额外需要undo purge 的老数据,所以TRX_UNDO_UPD_DEL_REC 是不需要purge 的。(老的二级索引还是由用户标记删除操作产生的TRX_UNDO_DEL_MARK_REC undo 删除掉。)
2,Undo Tuncate(trx_purge_truncate)
Undo Truncate 的主要触发逻辑是在trx_purge 中每一个purge batch处理完字后,按照一定的频率(srv_purge_rseg_truncate_frequency参数) 对于undo 进行truncate,主要调用函数 trx_purge_truncate。
Undo Truncate 的主要分为 rollback segment truncate 和undo sapce truncate。rollback segment truncate 主要是对于已经purge 干净的rollback segment 进行物理上的空间释放,具体调用trx_purge_truncate_rseg_history。undo sapce truncate,主要是对于整体都purge 干净的undo space 进行重建,回收整个space 的物理占用空间。(因为有可能undo 物理空间被撑的很大, 物理上空间回收通过undo space truncate 实现)。
void trx_purge_truncate() {
// rollback segment 的truncate
trx_purge_truncate_rseg_history();
// undo space 的truncate
// 如果这个undospace 大小大于srv_max_undo_tablespace_size 的大小,就可以触发undo truncate 逻辑, 首先要把这个space 标记成inactive
trx_purge_mark_undo_for_truncate();
// space 文件的删除重建,内部物理结构的初始化
trx_purge_truncate_marked_undo();// 8.0.18 函数是 trx_purge_truncate_marked_undo(); 8.0.13 函数是 trx_purge_initiate_truncate
}
void trx_purge_truncate_rseg_history() {
// 按照trx no 从小到大的顺序扫描这个rollback segment 上面的history list 上面的事务,直到扫描到的trx no 大于purge view 的trx no
// (意味着所有已经purge 的事务都物理格式都要处理一下)
// undo segment 标记 TRX_UNDO_TO_PURGE, 并且这个trx 已经是这个undo segment 的最后一个trx 了。
if ((mach_read_from_2(seg_hdr + TRX_UNDO_STATE) == TRX_UNDO_TO_PURGE) && (mach_read_from_2(log_hdr + TRX_UNDO_NEXT_LOG) == 0) {
// free undo segment, free 这个undo segment 使用一些undo record 占用的page。
// 并且调用trx_purge_remove_log_hdr 把事务从rseg 的historylist 摘掉
trx_purge_free_segment(rseg, hdr_addr, is_temp);
} else {
trx_purge_remove_log_hdr(rseg_hdr, log_hdr, &mtr);
}
}
3, Reference:
https://github.com/mysql/mysql-server/tree/mysql-8.0.13
https://github.com/mysql/mysql-server/tree/mysql-8.0.18
http://catkang.github.io/2021/10/30/mysql-undo.html
https://zhuanlan.zhihu.com/p/165457904