Innodb BLOB

前言
Innodb 使用的是B-tree 的形式来存储数据,这就意味着如果一个record 超过了单个page 的大小就没办法有效的索引。然而事实上blob 这种数据类型就是需要在一个record 里面存储相当大的数据。Innodb 内部使用了外部存储的方法来实现blob 的存储。在cluster record 里面只存储blob 的reference 索引,通常只有20bytes,通过这个索引会直接定位到外部存储的数据位置。这样解决了B-tree 不能够对于big record 高效索引的问题。这里基于Mysql 8.0.26 介绍了Blob 存储使用的各种物理数据结构,然后就其Insert ,Update,Delete 等接口进行详细的代码解析。最后对于Blob 的partical update 的优化进行了分析。
需要说明的是,8.0 版本对于blob 这种数据类型进行了比较大的重构,主要支持了Partical Update 的优化,与5.6 和 5.7 版本的blob 的物理数据结构有比较大的变动。这里的数据结构并不适用于5.6 跟5.7 版本。
数据结构
Blob 物理数据类型在内核中定义了三种page 类型,分别是first page ,index page 和data page,同时其在cluster key 当中存储的并不是真正的数据,只是自己定义的一个reference 。下边是各个数据类型的详细解释。
1,First page
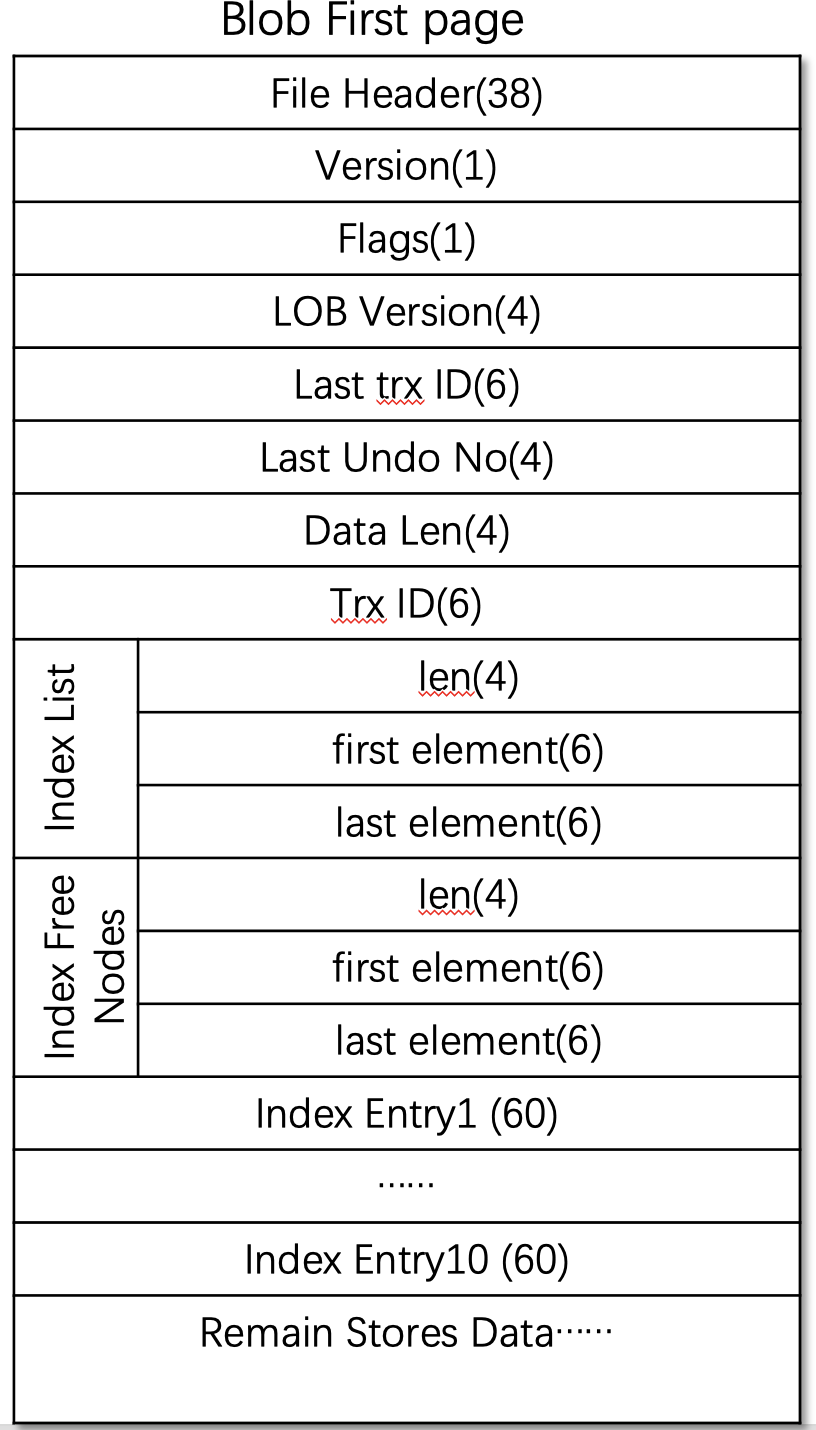
first_page_t
FIL_PAGE_DATA = 38;
OFFSET_VERSION = FIL_PAGE_DATA; 1byte(没什么用)
OFFSET_FLAGS = FIL_PAGE_DATA + 1; (mark can be partially updated)
OFFSET_LOB_VERSION = OFFSET_FLAGS + 1; 4bytes
OFFSET_LAST_TRX_ID = OFFSET_LOB_VERSION + 4; 6bytes(最后一次修改这个page 的trx id)
OFFSET_LAST_UNDO_NO = OFFSET_LAST_TRX_ID + 6;4bytes(最后一次修改这个page 的trx no)
OFFSET_DATA_LEN = OFFSET_LAST_UNDO_NO + 4; 4bytes
OFFSET_TRX_ID = OFFSET_DATA_LEN + 4; 6bytes (初始化first page 的时候用的trx id)
OFFSET_INDEX_LIST = OFFSET_TRX_ID + 6;
index_list
4Bytes FLST_LEN 0 /* 32-bit list length field */ 4bytes
6Bytes FLST_FIRST 4 /* (space + offset)of the first element of the list;
undefined if empty list */
6Bytres FLST_LAST (4 + FIL_ADDR_SIZE) /* the last element of the list;
undefined if empty list */
OFFSET_INDEX_FREE_NODES = OFFSET_INDEX_LIST + FLST_BASE_NODE_SIZE(4+ 2*6);
free list
4Bytes FLST_LEN 0
6Bytes FLST_FIRST 4
6Bytres FLST_LAST (4 + FIL_ADDR_SIZE)
LOB_PAGE_DATA = OFFSET_INDEX_FREE_NODES + FLST_BASE_NODE_SIZE(4+ 2*6);
10 index entries(by default), each index entry is of size 60 bytes.
(10* 60 = 600bytes)
index entry1
index entry2
...
index entry10
data_begin()=frame()+LOB_PAGE_DATA+node_count()*index_entry_t::SIZE (10*60);
LOB_PAGE_TRAILER_LEN = FIL_PAGE_DATA_END;
Index Entry

index_entry_t
OFFSET_PREV = 0; 6bytes
OFFSET_NEXT = OFFSET_PREV + FIL_ADDR_SIZE; 6bytes
/** Points to base node of the list of versions.*/
OFFSET_VERSIONS = OFFSET_NEXT + FIL_ADDR_SIZE;
4Bytes FLST_LEN 0
6Bytes FLST_FIRST 4
6Bytres FLST_LAST (4 + FIL_ADDR_SIZE)
OFFSET_TRXID = OFFSET_VERSIONS + FLST_BASE_NODE_SIZE; 6bytes
OFFSET_TRXID_MODIFIER = OFFSET_TRXID + 6; 6bytes
OFFSET_TRX_UNDO_NO = OFFSET_TRXID_MODIFIER + 6; 4bytes
OFFSET_TRX_UNDO_NO_MODIFIER = OFFSET_TRX_UNDO_NO + 4; 4bytes
OFFSET_PAGE_NO = OFFSET_TRX_UNDO_NO_MODIFIER + 4; 4bytes
OFFSET_DATA_LEN = OFFSET_PAGE_NO + 4; 4 bytes
OFFSET_LOB_VERSION = OFFSET_DATA_LEN + 4; 4bytes
SIZE = OFFSET_LOB_VERSION + 4;
2,Index Page

/** The node page (also can be called as the index page) contains a list of
index_entry_t objects. */
struct node_page_t : public basic_page_t;
OFFSET_VERSION = FIL_PAGE_DATA; 1byte
LOB_PAGE_DATA = OFFSET_VERSION + 1;
3,Data page

data_page_t
OFFSET_VERSION = FIL_PAGE_DATA; 1byte(好像没有用)
OFFSET_DATA_LEN = OFFSET_VERSION + 1; 4bytes
OFFSET_TRX_ID = OFFSET_DATA_LEN + 4; 6bytes
LOB_PAGE_DATA = OFFSET_TRX_ID + 6;
4,Reference
Cluster key 当中non-key fields 当中存放的是blob 自己的reference 固定长度20bytes。

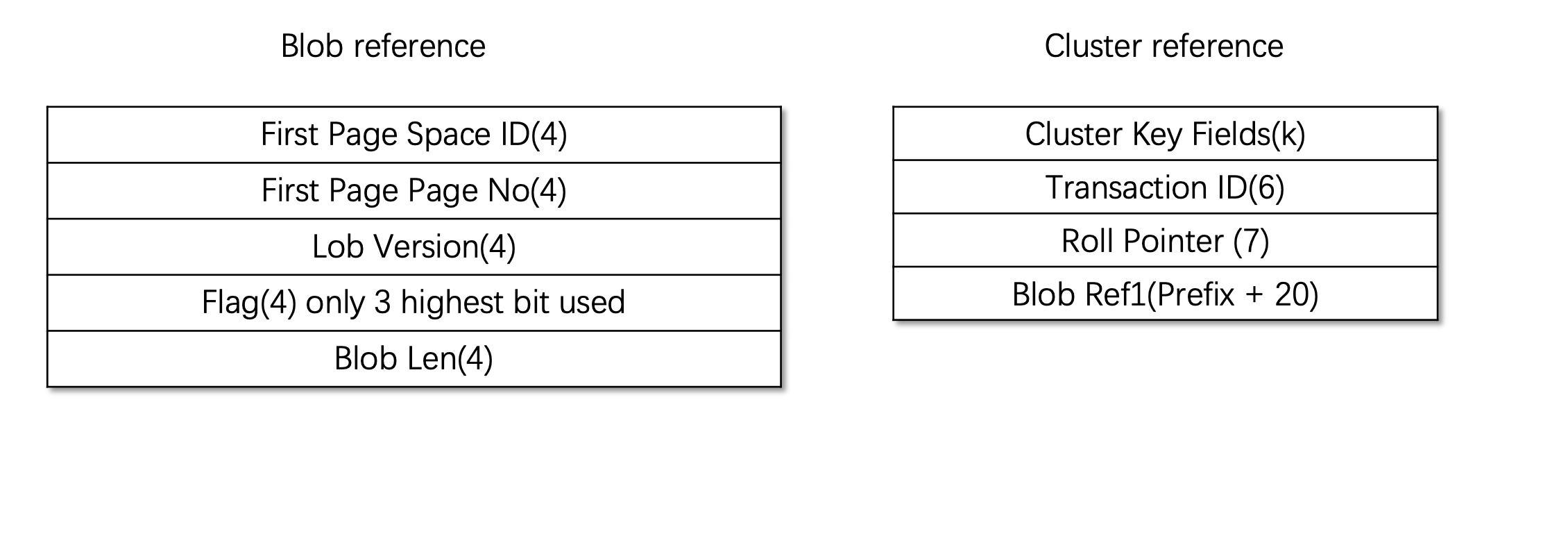
Ref_t
BTR_EXTERN_SPACE_ID = 0 4Bytes
BTR_EXTERN_PAGE_NO = 4. 4Bytes
/** offset of BLOB header on that page */
BTR_EXTERN_OFFSET = 8 4Bytes
/** Version number of LOB (LOB in new format)*/
BTR_EXTERN_VERSION = BTR_EXTERN_OFFSET; (这里新版本是代表lob version)
/** 8 bytes containing the length of the externally stored part of the LOB.
The 2 highest bits are reserved to the flags below. */
BTR_EXTERN_LEN =12 4Bytes
BTR_EXTERN_LEN 开始预留了4个bytes第一个byte的最高三位用作标记blob的状态分别是以下三种
BTR_EXTERN_LEN + 4 开始的4bytes 是blob的长度。
/** The most significant bit of BTR_EXTERN_LEN (i.e., the most
significant bit of the byte at smallest address) is set to 1 if this
field does not 'own' the externally stored field; only the owner field
is allowed to free the field in purge! */
const ulint BTR_EXTERN_OWNER_FLAG = 128UL;
/** If the second most significant bit of BTR_EXTERN_LEN (i.e., the
second most significant bit of the byte at smallest address) is 1 then
it means that the externally stored field was inherited from an
earlier version of the row. In rollback we are not allowed to free an
inherited external field. */
const ulint BTR_EXTERN_INHERITED_FLAG = 64UL;
/** If the 3rd most significant bit of BTR_EXTERN_LEN is 1, then it
means that the externally stored field is currently being modified.
This is mainly used by the READ UNCOMMITTED transaction to avoid returning
inconsistent blob data. */
const ulint BTR_EXTERN_BEING_MODIFIED_FLAG = 32UL; 标记是否正在被修改
REDUNDANT and COMPACT BLOB prefix is 768
DYNAMIC and COMPRESSED BLOB prefix is 0
Blob Ref 的长度是20
Code Analysis
Insert
通过以下三条命令可以观察blob insert的写入逻辑。
set debug = "+d, innodb_lob_print";
CREATE TABLE `blobtest` (
`id` int(11) NOT NULL,
`data` MediumBlob,
PRIMARY KEY (`id`));
insert into blobtest values(1, REPEAT('w', 1 * 16 * 1000 * 15));
其debug 打印输入如下:
[lob::print: trx_id=2665, avail_lob=240000, [ref_t: m_ref=, space_id=10,
page_no=5, offset=1, length=240000, is_being_modified=1, is owner=1,
is is_inherited0]
[n_entries=15,
[index_entry_t: node=, self=[fil_addr_t: page=5, boffset=96],
next=[fil_addr_t: page=5, boffset=156],
prev=[fil_addr_t: page=4294967295, boffset=0]]
[index_entry_t: node=, self=[fil_addr_t: page=5, boffset=156],
next=[fil_addr_t: page=5, boffset=216],
prev=[fil_addr_t: page=5, boffset=96]]
。。。
[index_entry_t: node=, self=[fil_addr_t: page=16, boffset=39],
next=[fil_addr_t: page=16, boffset=99],
prev=[fil_addr_t: page=5, boffset=636]]
。。。
[index_entry_t: node=, self=[fil_addr_t: page=16, boffset=279],
next=[fil_addr_t: page=4294967295, boffset=0],
prev=[fil_addr_t: page=16, boffset=219]]
]
Insert 了一个大概14个data page 大小的blob,它的first page 是page no 5, data page位于page no 6-15,对应的index 位于first page预留的10个index entry 里面,之后first page 的index entry 用尽,所以申请新的index page,page no16,data page no 17-20对应的index位于page no 16里面。
通过上述信息,构图如下:
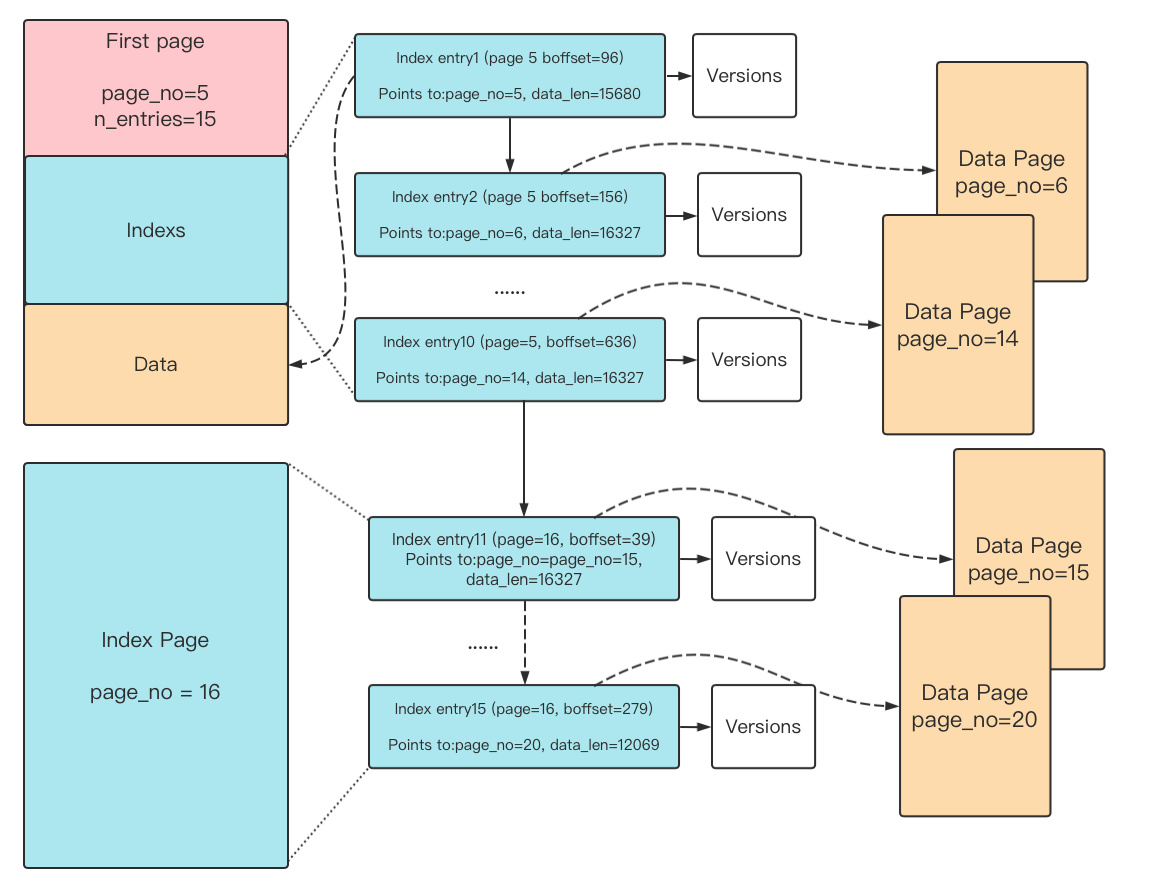
代码解析如下:
1, 分配一个first page,从buffer 中拷贝数据到first page 里面的data 部分,alloc first page 当中的第一个index entry, 这个index entry 的数据指向first page 的data部分。
2,如果数据还没有写完,不断的从first page 上面分配index entry,并且从fsp 上分配新的data page,将index entry 指向data page。从buffer 中拷贝到data page 里面。first page 上面预留了10个index entry,用尽了之后,会alloc 新的index page 。
dberr_t btr_store_big_rec_extern_fields(
trx_t *trx, btr_pcur_t *pcur,
const upd_t *upd, ulint *offsets,
const big_rec_t *big_rec_vec,
mtr_t *btr_mtr, opcode op) {
// upd 存放着SQL层面解析的数据,如果是json格式还存放partical update 需要更新blob 的
// offset 和len 以及数据 big_rec_vec 存放着需要存放insert 的数据
// pcur 当中存放了primary index record的内容,里面偏移一点量之后可以解析出来对应的这
// 一个blob ref
if (/*upd 当中判断是否要做partical update */) {
lob::update(ctx, trx, index, upd, field_no, blobref);
} else {
/* 如果一次更新太多就直接insert 一个新的blob*/
lob::insert(&ctx, trx, blobref, &big_rec_vec->fields[i], i);
}
}
dberr_t insert(...) {
// 从fsp当中分配一块内存
buf_block_t *first_block = first.alloc(mtr, ctx->is_bulk());
first.set_last_trx_id(trxid);
first.init_lob_version();
// 先写first page 当中装数据的部分
ulint to_write = first.write(trxid, ptr, len);
// alloc first page 当中的第一个index entry, 这个index entry 的数据指向first page
// 的data部分。
flst_node_t *node = first.alloc_index_entry(ctx->is_bulk());
while (remaining > 0) {
// 不断创建index entry,创建data_page_t。写入数据,把index entry 指向data_page_t
// 上面。
...
// 一定次数之后去commit 释放page锁,防止一个超级大的blob 把其他事务卡死。
// commit 之后再start 一个新的mtr
if (++nth_blob_page % commit_freq == 0) {
ctx->check_redolog(); //这里ctx 的m_block 是pcur 的block
ref.set_ref(ctx->get_field_ref(field->field_no));
first.load_x(first_page_id, page_size);
}
}
ref.update(space_id, first_page_no, 1, mtr); // 更新primary index record 中
// blob 的索引
}
Update
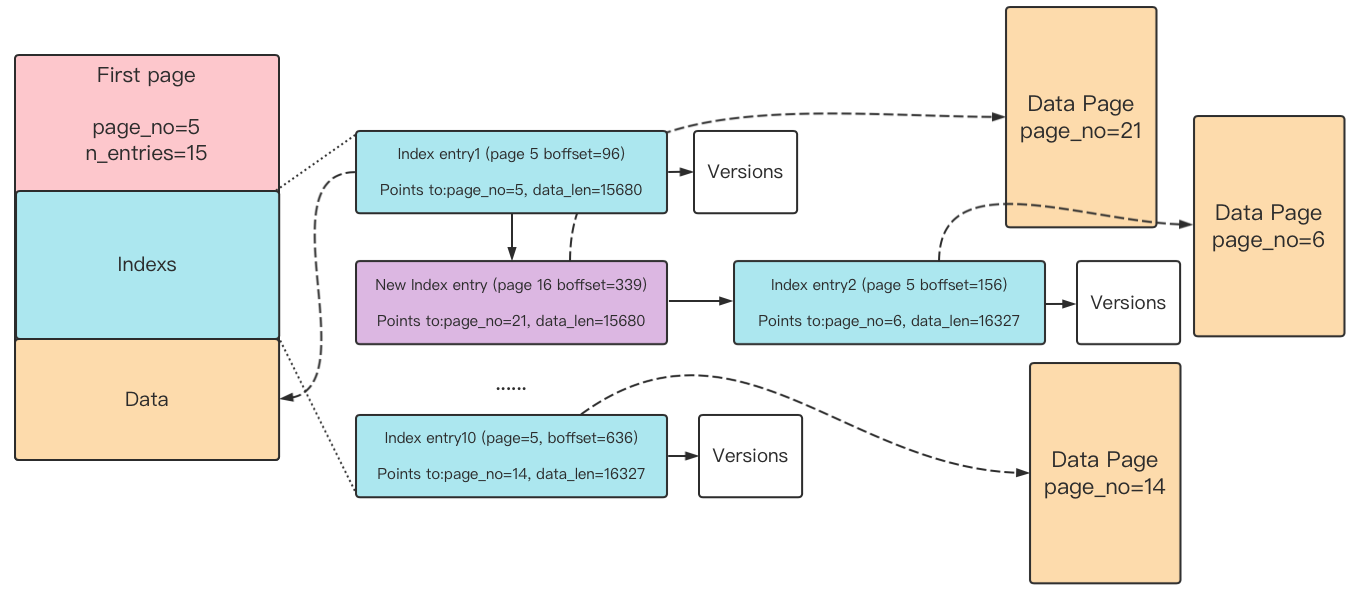
1, 判断能否原地update ,条件是upd里面计算的需要修改的bytes小于ref_t::LOB_SMALL_CHANGE_THRESHOLD(100bytes)
2,如果是原地更新, 调用replace_inline函数,根据first page 里面的index list 查找offset 的page。对这个page 对应的offset 数据进行覆盖。老数据存放在了undo 当中,如果mvcc 或者rollback,老的数据从undo 里面读取。
3,如果不是原地更新,调用replace函数。
3.1 查找page_offset 对应的index_entry位置,找到指向的data page,拷贝这个data page 到一个新的data page中。在新的page 当中完成从page_offset 开始的数据拷贝。申请一个new index entry 指向这个新的data page。
3.2 如果剩余数据量大于一个data_page的数据容量,直接new 一个新的data_page_t 更新数据,不需要再读原来的data_page。
3.3 如果还有剩余数据量小于一个data_page的数据,直接进行, Step3.1 中的步骤更新数据。
dberr_t update(...const upd_t *upd) {
// udp_t 是SQL层面处理使用的数据结构,SQL计算出了这次update 需要更新在Blob 中的offset
// 和len,以及需要更新的具体内容,存放在Binary_diff_vector
mtr_t *mtr = ctx.get_mtr();
first_page_t first_page(mtr, index);
//first page x锁
first_page.load_x(first_page_id, page_size);
for (Binary_diff_vector) {
if (small_change) {
err = replace_inline();
} else {
err = replace();
}
}
blobref.set_offset(lob_version, mtr);
//mtr 没有commit 交给上层commit
}
static dberr_t replace_inline() {
// 拿X锁,从index_list 找到对应的offset, load data_page_t 加x 锁, 原地更改数据。
}
dberr_t replace() {
// 查找page_offset 对应的index_entry_t位置,大概率是一个data_block_t 的中间位置
// 直接读上来x 锁,然后拷贝这个page 到新的data_block_t当中, 在新的page 当中完成
// 从page_offset 开始的数据拷贝。(如果找到的是first_page_t新建一个data_page_t,
// 拷贝first_page_t 的数据部分到data_page_t当中)。
...
// 如果剩余数据量大于一个data_page_t 的数据容量,直接new 一个新的data_page_t 更
// 新数据,不需要再读原来的data_page_t
...
// 如果还有剩余数据量小于一个data_page_t 的数据,直接进行开始步骤中的步骤更新数据。
}
Read
1,从Blob reference中解析出first page 的地址,load first page。
2,沿着first page 的index list 遍历数据。
2.1,如果读到的当前index entry的version 大于blob ref 的version,说明不应该读到当前version的数据,应该沿着当前index entry 的versions_list 横向查找小于blob ref version的index entry。
2.2,读取index entry 指向的data page。放入返回buffer 当中。
ulint read(ref_t ref, ...) {
first_page_t first_page(&mtr, ctx->m_index);
// 找到first_page_t 加s锁,找到index list 中的第一个index entry
first_page.load_s(page_id, ctx->m_page_size)
...
const uint32_t lob_version = ref.version();
flst_base_node_t *base_node = first_page.index_list();
fil_addr_t node_loc = flst_get_first(base_node, &mtr);
// 沿着index entry 链表遍历数据
while (!fil_addr_is_null(node_loc) && want > 0) {
// 将读到的index entry的page 加s锁记录到first page 的mtr当中。
...
const uint32_t entry_lob_version = cur_entry.get_lob_version();
if (entry_lob_version > lob_version){
while (!fil_addr_is_null(node_versions)) {
// 当前index entry 的version 大于blob ref的version,说明不应该读到当前version
// 的数据,应该沿着versions_list 横向查找小于blob ref version的index entry
}
// 读取找到的data_page_t 的数据。加s锁记录到data_mtr 中。
...
// commit data_mtr 的锁资源
if (++data_pages_count % commit_freq == 0) {
mtr_commit(&data_mtr);
mtr_start(&data_mtr);
}
}
}
mtr_commit(&mtr);
mtr_commit(&data_mtr);
}
Delete
1, 先删除old version,如果这个index entry 是由这个undo 对应的操作(trx_id 和undo_no 一致)造成的,删除这个老版本的index entry 对应的data page。
2,如果这个undo 对应的操作是这个blob 最后一次操作,意味着这个blob 不需要了,可以整体删除。(场景可以考虑 insert,整体update,最开始的insert 对应的blob 就可以整体删除)。
void purge(DeleteContext *ctx, dict_index_t *index, trx_id_t trxid,
undo_no_t undo_no, ref_t ref, ulint rec_type,
const upd_field_t *uf) {
// get first page id from ref
page_no_t first_page_no = ref.page_no();
page_id_t page_id(space_id, first_page_no);
// load first page
first.load_x(page_id, page_size);
// 遍历这个blob 所有old versions,如果这个index entry 是这个undo 修改的,那么可以删除
// 这个index entry 对应的data page。
if (vers_entry.can_be_purged(trxid, undo_no)) {
ver_loc = vers_entry.purge_version(index, trxid, vers, free_list);
}
// 如果这个undo 对应的是最后一次修改那么这个blob 整体都可以删除
bool ok_to_free = (rec_type == TRX_UNDO_UPD_EXIST_REC) &&
!first.can_be_partially_updated() &&
(last_trx_id == trxid) && (last_undo_no == undo_no);
if (rec_type == TRX_UNDO_DEL_MARK_REC || ok_to_free) {
ut_ad(first.get_page_type() == FIL_PAGE_TYPE_LOB_FIRST);
first.free_all_data_pages();
first.free_all_index_pages();
first.dealloc();
}
}
Partical Update Optimization
考虑场景,每一次修改1bytes,如果没有Inline update,每一次都要copy 原有的一个page 的数据,产生一个新的data page(因为需要保留旧数据需要做mvcc),这样的效率非常低。
如果在原有的数据上inline update,考虑到mvcc的需要,旧的数据需要地方存储,这个优化 把小于ref_t::LOB_SMALL_CHANGE_THRESHOLD(100bytes)更新的老数据放到了undo rec 里面。这样可以避免每一次都是小更新时候每一次都读写取整个page。
Undo record
undo record 当中存放着old column 的数据便于回滚跟mvcc 等操作,每个old column 由
<field no, field len, value> 组成。非外部存储流程,update 类型的undo record 需要存储old column 的个数,然后存储各个列的old field_no,field_len, value。
对于外部存储流程field_no字段没有变化, 在field_len 和value字段进行了重新设计,写入undo rec的时候在field_len写入UNIV_EXTERN_STORAGE_FIELD,之后再写入真正的长度 。读取的时候判断字段长度如果是UNIV_EXTERN_STORAGE_FIELD 那么其真正的len 在其后面一个字段,并且接下来的value是blob格式是需要按下面格式解析。

如果有外部存储
trx_undo_page_report_modify_ext_func 函数写入field length 和 取出lob prefix with the lob ref (20bytes)
trx_undo_report_blob_update 函数负责写入 图中1byte flag 以及之后的所有部分。
trx_undo_page_report_modify_ext_func(
trx_t *trx,
dict_index_t *index,
byte *ptr,
byte *ext_buf, 存储外部undo数据的buf
ulint prefix_len, 存储外部undo 数据的最大的长度
const page_size_t &page_size,
const byte **field, old 主键索引当中存储的值(包含blob ref)
ulint *len, old 主键索引记录的blob 的长度
spatial_status_t spatial_status){
if (ext_buf) {
ptr += mach_write_compressed(ptr, UNIV_EXTERN_STORAGE_FIELD);
ptr += mach_write_compressed(ptr, *len);
// 取prefix 这个应该是blob 做索引的情况
// => btr_copy_externally_stored_field_prefix_func
*field = trx_undo_page_fetch_ext(trx, index, ext_buf, prefix_len,
page_size, *field, is_sdi, len);
ptr += mach_write_compressed(ptr, *len + spatial_len);
}
}
/** Write the partial update information about LOBs to the undo log record */
trx_undo_report_blob_update() {
// write 1byte for future use
...;
if (!small_change) {
/* This is not a small change. So write the size of the vector as
0 and bailout. */
undo_ptr += mach_write_compressed(undo_ptr, 0);
DBUG_RETURN(undo_ptr);
}
// writ vector size
// write first page no
// write first page lob version
// write last trx id
// write last undo no
for () {
// write lob diff vector
}
}
至此,关于Blob 物理数据结构的梳理基本上就完结了。
Reference
https://github.com/mysql/mysql-server/tree/mysql-cluster-8.0.26
https://dev.mysql.com/blog-archive/mysql-8-0-optimizing-small-partial-update-of-lob-in-innodb/
https://dev.mysql.com/blog-archive/externally-stored-fields-in-innodb/
https://dev.mysql.com/blog-archive/mysql-8-0-new-storage-format-for-compressed-blobs/
https://dev.mysql.com/blog-archive/mysql-8-0-innodb-introduces-lob-index-for-faster-updates/
https://dev.mysql.com/worklog/task/?id=8960
https://dev.mysql.com/worklog/task/?id=11328
https://developer.aliyun.com/article/598070