Raft优秀实现之Floyd
0,概述
Floyd是奇虎基础架构团队自研的一致性库。主要致力于对于敏感信息的一致性维护,目前应用于Zeppelin的mtea信息存储,上线运行近两年,目前比较平稳。由于Floyd代码是忠于Raft论文的原生实现,所以跟Raft论文相互印证之下,非常有助于理解Raft论文。如果你需要实现一个一致性服务,或者是一致性理论的初学者,强烈建议Floyd。整个库大约2000行代码,整个Raft的流程非常清晰。
Floyd 依赖于自研网络库 pink,pink主要提供网络层的client和server封装实现。Floyd实例之间的通信主要通过protobuf协议传递。因此floyd还依赖于prtobuf。同时由于所有的信息需要落盘,处于性能考虑,floyd把这些信息存在了RocksDb上,因此floyd依赖于rocksdb。
1,整体架构
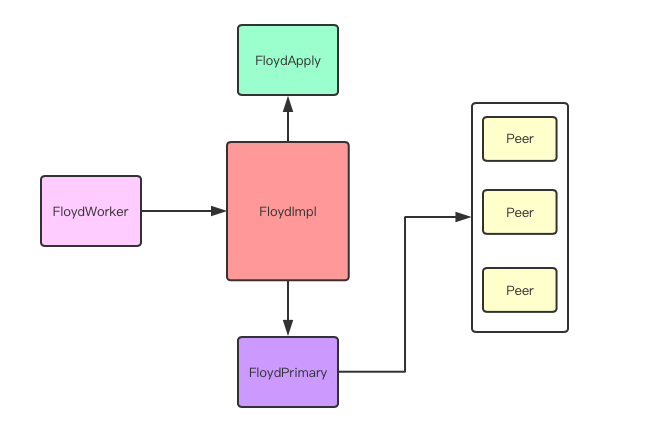
FloydWoker线程: 主要负责网络链接的建立,相应调用Floyd类的处理方法。
FloydImpl类: 主要包括了Raft内部RPC的处理办法。包括处理收到的RequestVote消息和AppendEntries消息。
FloydApply 线程:主要实现Apply Log Into State Machine那部分逻辑,基本上就是把上层数据写入rocksdb。
FloydPrimary 线程:主要负责配合Peer线程完成状态机器转换。如下图所示。
Peer线程:主要向Peer Floyd发送RequestVote,AppendEntries消息并且处理相应的response。
2,Floyd初始化
Floyd作为库函数,上层逻辑需要调用Floyd::Open() 对其初始化。初始化流程如下
Status Floyd::Open(const Options& options, Floyd** floyd) {
FloydImpl *impl = new FloydImpl(options);
Status s = impl->Init();
}
Status FloydImpl::Init() {
// init client_pool_, used to send to floyd peer
worker_client_pool_;
// db_ used to write committed data
rocksdb::DB::Open(db_);
// log_and_meta_ used to write raft log and raft meta
// log:
// kv{last_log_index_, entry}
// meta:
// static const std::string kCurrentTerm = "CURRENTTERM";
// static const std::string kVoteForIp = "VOTEFORIP";
// static const std::string kVoteForPort = "VOTEFORPORT";
// static const std::string kCommitIndex = "COMMITINDEX";
// static const std::string kLastApplied = "APPLYINDEX";
rocksdb::DB::Open(log_and_meta_);
// used to write raft log
raft_log_(log_and_meta_);
// used to write raft meta
raft_meta_(log_and_meta_);
// send req to peer
primary_(peers_, raft_meta_);
// handle client request
worker_;
// write to db
apply_(db_, raft_meta_, raft_log_);
primary_->AddTask(kCheckLeader);
}
Floyd 将committed之后的数据存到rocksdb当中(db_)。同时用另一个rocksdb保存raft log和raft需要落盘的 meta。之后启动各个线程。
3,处理RequestVoteRPC
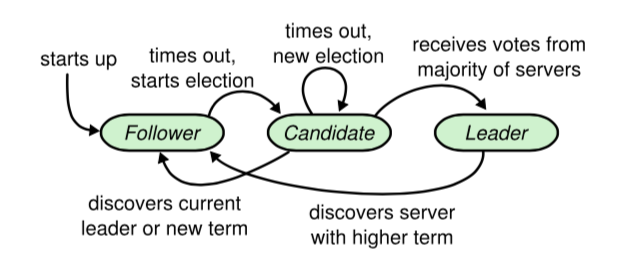
FloydPrimary线程处理定时任务发现节点作为Folower角色超时,角色转换为Candidate开始发送RequestVoteRPC。
void FloyPrimary::LaunchCheckLeader() {
if (timeout) {
// current term ++
context_->BecomeCandidate();
raft_meta_->SetCurrentTerm, VotedForIp, VotedForPort;
// send this task to all peers
NoticePeerTask(kHeartBeat);
}
}
具体的RequestVoteRPC发送在Peer线程中完成。
// send/recv RequestVoteRPC
void Peer::RequestVoteRPC() {
Status result = pool_->SendAndRecv(peer_addr_, req, &response);
if (response.term() > context_->current_term) {
// set local term to be response term
context_->BecomeFollower(res.term());
} else if (res.term() < context_->current_term) {
// Ingore old term rsp
return;
}
if (context_->role == Role::kCandidate) {
if (response.vote_granted() == true){
if (received majority of votes) {
context_->BecomeLeader();
// send heartbeat to peer immediately
primary->AddTask(kHeartbeat, false);
}
}
}
else {
return;
}
}
收到对端Floyd回复的报文之后:
如果对端Floyd的Term比自己current_term大,自己主动变成Follower。
如果对端FloydTerm比自己小,本地不处理这个消息。
如果自己是Candidate 并且获得了半数以上的投票,自己可以变成leader,同时马上向所有Peer发送HeartBeat声明自己是主。

对端Floyd收到RequestVoteRPC后的处理逻辑如下:
// recv RequestVoteRPC
int FloydImpl::ReplyRequestVote() {
/*
* If RPC request or response contains term
* T > currentTerm: set currentTerm = T, convert to follower (5.1)
*/
if (request_vote.term() > context_->current_term) {
context_->BecomeFollower(request_vote.term());
context_->voted_for_ip.clear();
context_->voted_for_port = 0;
// persist value above
}
if (request_vote.term() < context_->current_term) {
BuildRequestVoteResponse(context_->current_term,
granted(false), response);
return -1;
}
raft_log_->GetLastLogTermAndIndex(&my_last_log_term, &my_last_log_index);
// If votedFor is null or candidateId, and candidate’s log is at
// least as up-to-date as receiver’s log, grant vote (§5.2, §5.4)
if ((request_vote.last_log_term() < my_last_log_term) ||
((request_vote.last_log_term() == my_last_log_term) &&
(request_vote.last_log_index() < my_last_log_index))) {
BuildRequestVoteResponse(context_->current_term,
granted(false), response);
return -1;
}
if (!context_->voted_for_ip.empty() || context_->voted_for_port != 0) {
BuildRequestVoteResponse(context_->current_term,
granted(false), response);
return -1;
}
// greand this vote
context_->voted_for_ip = request_vote.ip();
context_->voted_for_port = request_vote.port();
raft_meta_->SetVotedForIp(context_->voted_for_ip);
raft_meta_->SetVotedForPort(context_->voted_for_port);
context_->last_op_time = slash::NowMicros();
BuildRequestVoteResponse(context_->current_term, granted(true), response);
return 0;
}
对端收到RequestVoteRPC后:
如果对端term大于本地term自己变成Follower。
如果对端term小于本地term对本次RequestVoteRPC投反对票。
如果已经对其他Floyd投票或者对端不是up-to-date,对本次RequestVoteRPC投反对票。
如果之前没有投反对票的理由,投同意票,同时设置本地参数。
4,处理AppendEntriesRPC
选举过程之后,开始处理正常的读写请求。
FloydWoker线程收到上层逻辑请求(例如写kv)时候,直接调用FloydImpl接口进行Entry的同步和应用状态机。
// send write command to worker
Status FloydImpl::ExecuteCommand() {
uint64_t last_log_index = raft_log_->Append(entries);
if (options_.single_mode) {
// only one floy instance
} else {
primary_->AddTask(kNewCommand);
}
{
slash::MutexLock l(&context_->apply_mu);
// wait for primary apply this append log just now
while (context_->last_applied < last_log_index) {
if (!context_->apply_cond.TimedWait(1000)) {
return Status::Timeout("FloydImpl::ExecuteCommand Timeout");
}
}
}
}
FloydWorker 调用ExecuteCommand,驱动Peer线程发送AppendEntriesRPC,Apply线程写db,同时阻塞自己同步等待这个请求被应用到状态机(kv写入db)。
Peer 同步线程处理AppendEntriesRPC流程如下
void Peer::AppendEntriesRPC() {
// BuildAppendEntryRPC
...;
// add entrys
// TODO(AZ) cause this expensive batch op, follower may timeout
for (uint64_t index = next_index_; index <= last_log_index; index++) {
raft_log_->GetEntry(index, tmp_entry);
Entry *entry = append_entries->add_entries();
*entry = tmp_entry;
// max bytes or log num per RPC
// cur option 1MB or 3500
if (num_entries >= options_.append_entries_count_once
|| (uint64_t)append_entries->ByteSize()
>= options_.append_entries_size_once) {
break;
}
}
pool_->SendAndRecv(peer_addr_, req, &res);
// if we may get a larger term, and transfer to follower
...;
if (context_->role == Role::kLeader) {
if (success) {
match_index_ = prev_log_index + num_entries;
// only log entries from the leader's current term are committed
// by counting replicas
if (append_entries->entries(num_entries - 1).term()
== context_->current_term) {
// get commit index from all peers
AdvanceLeaderCommitIndex();
apply_->ScheduleApply();
}
next_index_ = prev_log_index + num_entries + 1;
} else {
// do next_index_ roll back
// roll back 1 or to follower last_log_index pos
uint64_t adjust_index =
std::min(res.append_entries_res().last_log_index() + 1,
next_index_ - 1);
if (adjust_index > 0) {
// Prev log don't match, so we retry with more prev one according to
// response
next_index_ = adjust_index;
AddAppendEntriesTask();
}
}
} else {
return;
}
}
创建需要同步到follower的entry,为了防止一次同步太多entry导致超时,限制了每次只能同步固定条数的entry或者固定大小的entry。
发送AppendEntriesRPC到对端,同步等待Response。
如果对端回复成功,更新leader保存的peer log 同步指针。如果同步entry的term等于当前term,这些entry在大多数peer返回之后可以被应用到状态机。
如果对端返回失败,这个peer的同步指针位置,用更老的位置同步。

Follower收到AppendEntriesRPC的处理流程
// recv AppendEntries
int FloydImpl::ReplyAppendEntries() {
if (append_entries.term() < context_->current_term) {
// if my current term is larger, return my current_term
} else if ((append_entries.term() > context_->current_term)
|| (append_entries.term() == context_->current_term &&
(context_->role == kCandidate ||
(context_->role == kFollower &&
context_->leader_ip == "")))) {
// if sender term is larger or i dont know who is my leader
// become sender's follower
context_->BecomeFollower(append_entries.term(),
append_entries.ip(), append_entries.port());
}
if (append_entries.prev_log_index() > raft_log_->GetLastLogIndex()){
// if prev_log_index not found in local
// return my raft_log_->GetLastLogIndex()
}
if (append_entries.prev_log_index() < raft_log_->GetLastLogIndex()) {
raft_log_->TruncateSuffix(append_entries.prev_log_index() + 1);
}
// compare sender's prev index and term with my last log index and term
if (append_entries.prev_log_term() != my_last_log_term) {
// conflicts with a new one, delete the existing entry
// and all that follow it
raft_log_->TruncateSuffix(append_entries.prev_log_index());
return -1;
}
// batch append entry to raft_log
...;
if (append_entries.leader_commit() != context_->commit_index) {
context_->commit_index = std::min(leader_commit,
raft_log_->GetLastLogIndex());
raft_meta_->SetCommitIndex(context_->commit_index);
apply_->ScheduleApply();
}
BuildAppendEntriesResponse(success(true));
return 0;
}
如果报文term比自己当前的term小,返回自己当前的term。
如果报文term比自己当前的term大,或者节点不知道自己当前的leader是谁,变成这个节点的从。
如果报文的prev_log_index 比自己当前的last_log_index还要大。返回自己的last_log_index.
如果报文的prev_log_index 比自己当前的last_log_index小,自己回退到这条log上。
如果报文的prev_log_term和自己的last_log_term不相等。删除所有在prev_log_index之后的entry。
应用entry到本地,异步应用状态机。返回Leader成功。
总体来说Floyd的实现比较忠于论文实现,对于Raft的初学者,或者基于Raft论文的开发人员是非常好的学习素材。Floyd实现被收录于https://raft.github.io