DSQL OVERVIEW
整体架构
DSQL 的整体架构由,5层组成, 分别是Transaction and session router,Query Processor,Adjudicator,Journal, Storage 组成。其主要的设计的方式是尽可能的实现serverless,他的每个组件全都是分布式的, 可以快速的弹升弹降。其中比较新颖的地方是其处理冲突的方式是使用事务级别的OCC (Optimistic Concurrency Control)方式,由于减少了冲突检测的次数,DSQL 可以适用于跨Region 级别的多写场景。
事实上跨Region 级别的多写,最主要的问题就是处理冲突, 有可能是row, page, trx 级别的冲突。对于如何处理冲突,可以是避免产生冲突, 也可以是处理已经产生的冲突。对于处理已经产生的冲突,RDS 通过binlog 双向同步的方式实现多写,出现冲突会导致复制中断,而且由于造成冲突的场景不一样,修复的难度是比较大的。
对于避免产生冲突, 可以使用多region 分表,分区的方式,让每个region 写入固定的表/分区,从根本上避免冲突。但是这需要用户在使用上做适应性改造,需要规划好每个Region 使用的表/分区。另一种避免产生冲突的方式就是集中拿锁,通过拿锁的方式来限制row/page 不会同一时刻双写。但是对于跨Region 的场景,对于比较细颗粒度的资源拿锁是非常耗时的。另一种处理已经产生的冲突是这里讨论的OCC 的方式,通过乐观的方式在事务要提交的时候,进行冲突检测,如果在事务存在的期间内没有人修改这个事务修改的row,那这个事务就可以提交。也是保证同一时间只能有一个事务写这些row。但是这种情况下,用户的事务在冲突检测失败的情况下会整体回滚,业务层面需要重试。并且由于是基于OCC,业务层面使用上也应该合理的规划对于某些row 的使用方式, 避免频繁的产生事务回滚。
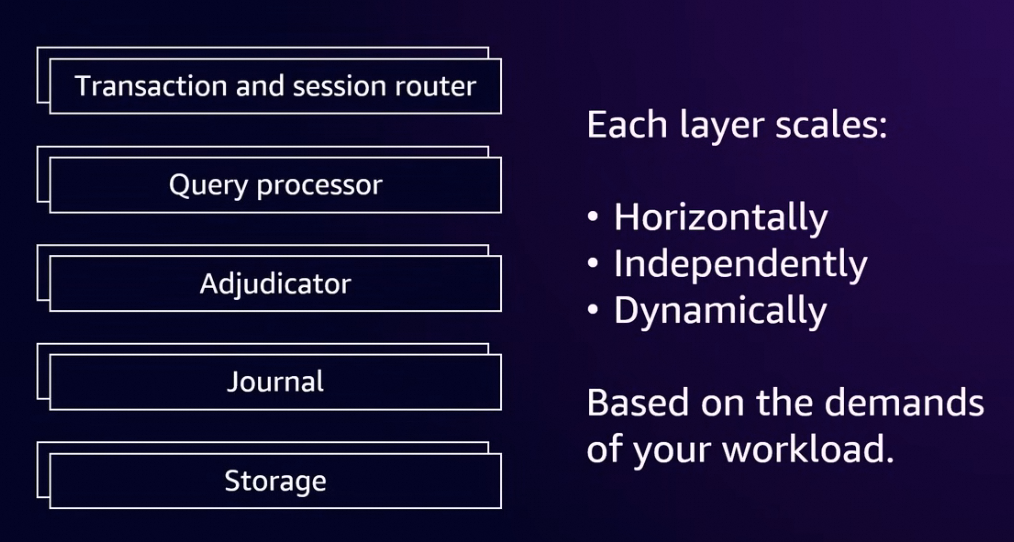
DSQL 的5层组件
Transaction and session router:
这部分DSQL 给每一个session 分配一个微型虚拟机(firecracker), 内部运行Query Procesor,根据DSQL 作者 Marc Brooker 的说法, 每个session 创建的时候,firecracker 可以在个位数毫秒级别弹起来一个虚拟机, 专门处理这个session 的事务。
Query Processor:
用的PostgreSQL 原生的部分, 主要负责sql 的解析等工作,其内部会缓存这个session 内未提交的事务的修改。本身是无状态的,水平扩展。
Adjudicator:
DSQL 主要实现OCC 的部分。 主要负责事务级别的冲突检测。QP 在事务结束的时候告诉Adjudicator 要写那些keys/rows, 如果在这个事务的存活期间没有其他的事务对这些keys 修改,那就可以commit 到 Journal 当中。分片的范围可能跟范围内的key 多少分裂合并。并且每个分片有是有Leader/slave的, leader 的选出是Adjudicator负责这个分片的leader/slave自己选举产生的。最终记录在PG 的catalog table 表结构当中。
Adjudicator 组件本身是按照key 分片的。猜测可能的分片范围类似
[DB/Table/cluster_index/abc/ , DB/Table/cluster_index/abd]
Journal:
WAL (write ahead log)用于故障恢复。Commit 的事务到这里就可以认为是commit 成功了。Journal 这里都是存储的是已经commit 的事务。猜测失败的事务直接就在QP 内存回滚掉了(故障恢复相对容易一点)。
Storage:
Storage 是分布式的, 存储层里面有对于同一个row 的不同版本的数据,使用的是 snapshot isolation, 应该类似于PostgreSQL REPEATABLE READ,存在多个版本的数据的完整数据。
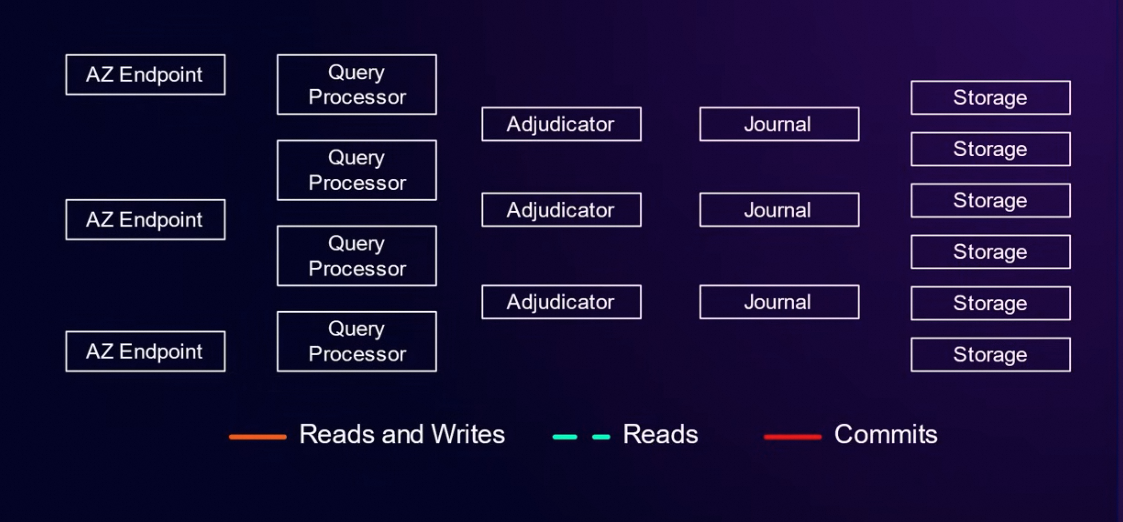
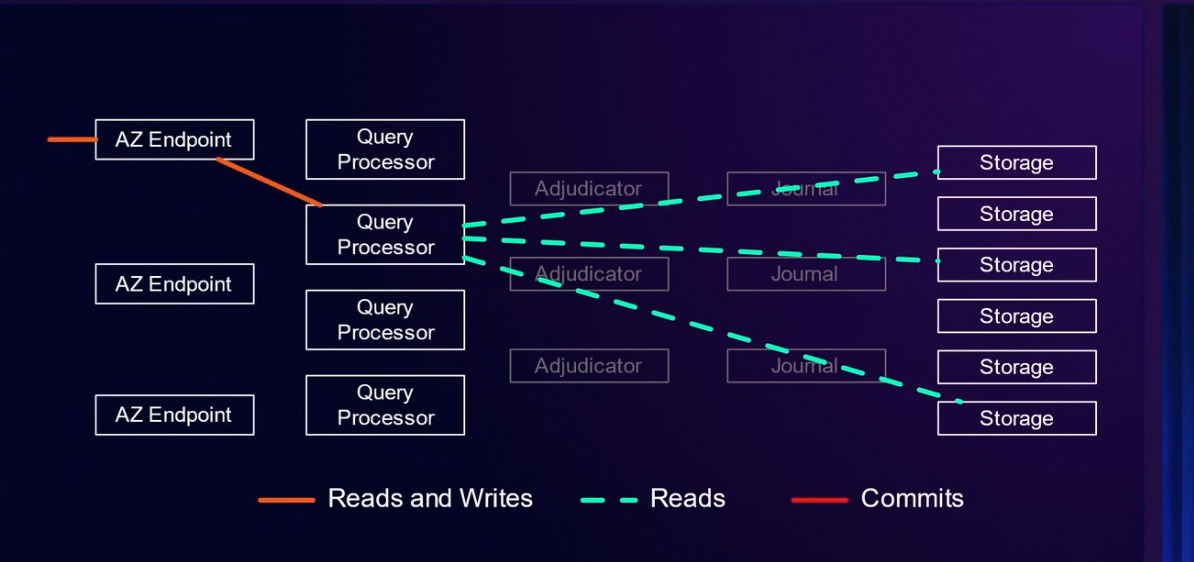
读请求路径:
读请求不用判断冲突跟落盘,所以直接跨过Adjudicator 跟 Journal,请求直接打到Storage 上面。DSQL 每个事务有精确的Tstart ,基于EC2 有一个时钟服务(precision time infrastructure),读sql 在storage 上面就可以根据Tstart 确定读取的版本,为了减少Query Processor 到Storage 的频繁网络请求, QP 到storage 的请求都是logical interface , 请求row 而不是page。比如一些过滤条件直接传给存储。
猜测:其间使用的接口可能是PostgreSQL 的 Foreign Data Wrapper (FDW) 扩展机制。QP 向storage 请求类似SQL 的语句,storage 本身也不一定只是存储, 也有可能是一个本地的PG 实例。

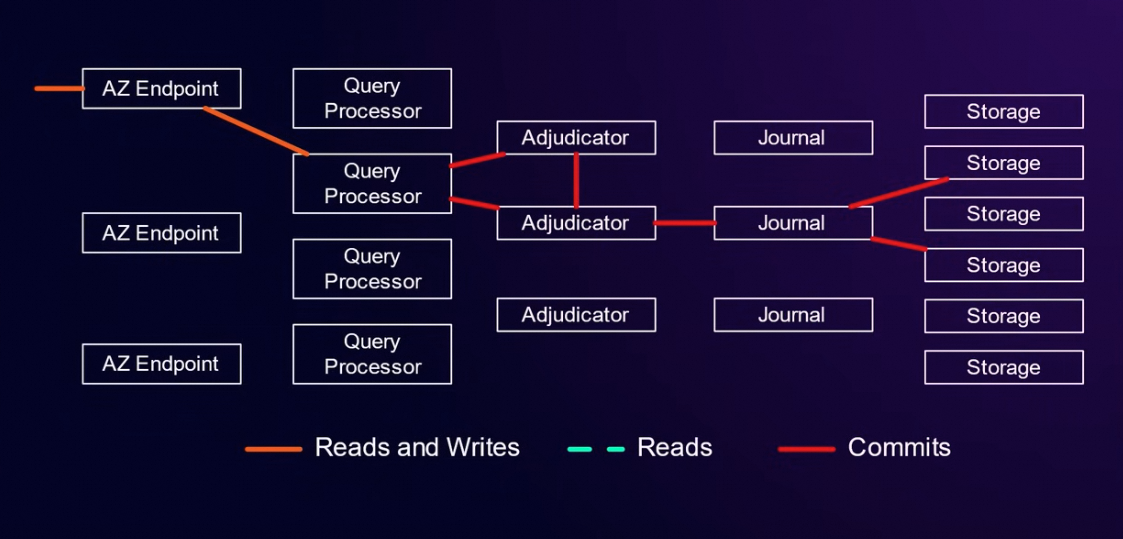
写请求路径:
写事务开启事务时间Tstart,这个事务的任何数据修改是先缓存到QP 当中, 猜测这也是单个事务有修改不过3000行的限制的由来。等到事务要Commit 的时候,QP 联系某一个 Adjudicator A ,A 把这个事务修改的row 发送到负责这些 row 的Adjudicators,如果没有人在Tstart 之后修改这个事务要修改的内容, A就去通知其他的 adjudicator 这个事务要在Tcommit 做commit。等其他adjudicator都收到这个通知,A 再将这个事务写到 Journal,这里就可以返回用户了。后台会异步把journal 应用到storage。
后续如果有读的话, 假设storage 存的row 的版本是t5, t10 时候的版本, journal 里面有这个row 的t12 版本。这时候有一个Tstart = t13 的读请求,到sotrage 理想情况下应该是等到 t13以前的数据都应用完。 要不然,这个请求直接读应该是读到t10 的版本, 等t12 版本应用完,读到的又是t12 版本。
猜测:
例如Trx1 Tstart=10 修改了k1,k2 , 去Adjudicator 去判断Tstart 到当前时间有没有人修改k1,k。 如果没有,就直接给这个Trx1 一个Tcommit 比如说等于50,Trx1 后续流程走完提交成功。之后,如果有一个Trx2, 在Tstart =20 修改了k1,这时候Ajudicator 会发现之前Trx1 在 Tcommit = 50 对这个key 进行了修改,Tstart= 20是在上次commit 修改之前的修改,所以不能提交。按照这样的实现方式, 为了保证一个时间段对于某一个key的写入只能有一个trx。
对于长事务,如果事务长时间不结束,因为不知道这个长事务会在这个事务内部修改什么key,那么Adjudicator 需要保留非常长时间的key 的最后一次修改时间,这样可能会造成非常大的内存占用。所以 DSQL 还有限制, 事务的时间不能超过5mins, 也就是Adjudicator 需要保存5min 内对于所有key 的修改。

Multi Region
目前的版本支持2个Region 和一个witness region。如图中的Region A,C 是用户可使用的Region ,Region B 是witness region, 用户防止网络问题产生的分布式组件的脑裂。
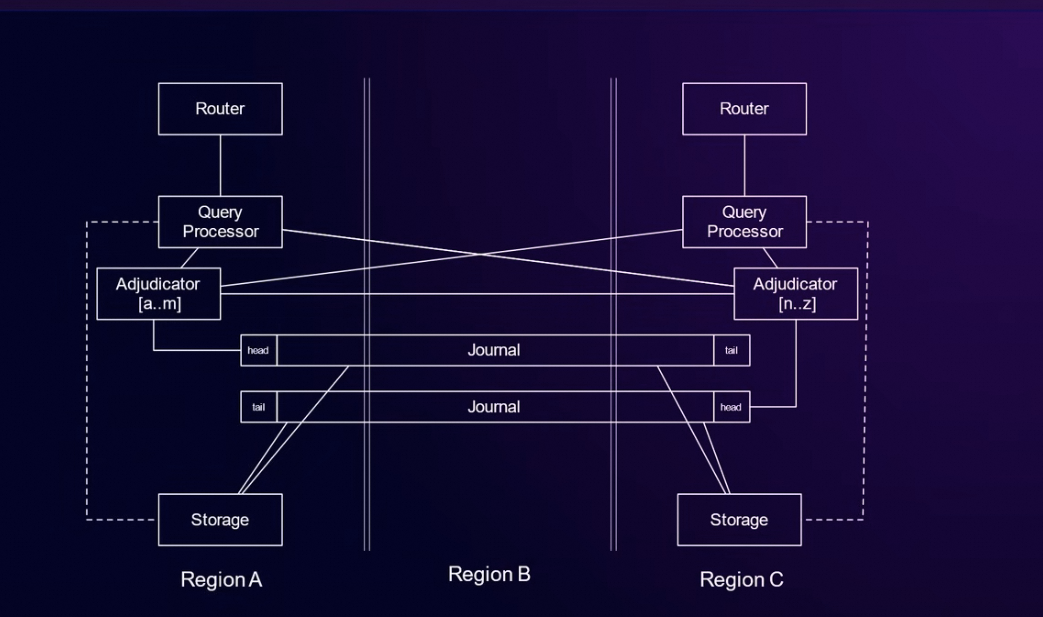
这时候Adjudicator 是跨Region 部署的, Storage 依旧是本地部署的。所以读请求还是读本地的,
写请求场景,如果key 落到了peer region 的Adjudicator 负责的key slot 中,可能还需要走一次网络做跨 region 协调。理论上如果修改的是自己Adjudicator 负责的key slot 可以不走网络。事实上测试显示这里的写请求还需要走两次网络。(后面会具体分析)
测试&分析:
环境:AWS EC2 美东美西延迟大概 50ms (往返延迟)。美东美西各一个DSQL 组成Multi Region DSQL。
1,OCC 相关验证
1.1 DDL 冲突,美东美西同时做ddl,后做的会报错
ERROR: schema has been updated by another transaction, please retry: (OC001)
做成功的延迟大概在120ms -180ms 。这里DSQL 限制同一时间只能有一个DDL 在执行。
1.2 DML 冲突, 美东美西在事务内对同一行进行修改。后写的会报错
ERROR: change conflicts with another transaction, please retry: (OC000)
失败的事务耗时在50ms 左右,这里只是 Adjudicator 协调的时延。
1.3 验证事务不能超过5min限制
超过5min 的事务提交会自己rollback。这里猜测是为了防止 Ajudicator缓存过多内容,这里给一个最长事务限制, Ajudicator只缓存5min 内的row 修改。
postgres=> begin;
BEGIN
postgres=*> update t1 set name = 'bbbbb' where id =2;
UPDATE 1
...(5mins)
postgres=*> update t1 set name = 'bbbbb' where id =3;
ERROR: transaction age limit of 300s exceeded
DETAIL: Current transaction age 365s exceeds 300s
postgres=!> commit;
ROLLBACK
1.4 验证单个事务修改行数小于3000限制。猜测这里对于一个事务的修改commit 之前是缓存到QP 当中的, 给一个事务修改行数的限制是防QP 占用过多内存。
postgres=> update sbtest1 set k = 200 where id < 3002;
ERROR: transaction row limit exceeded
1.5 验证不支持READ UNCOMMITTED
猜测目前的事务内修改是暂时记录到QP当中的, OCC提交成功之后才会应用到 Journal 当中。所以是不能支持read uncommitted 的。(不过支不支持也没人需要)
postgres=> SET LOCAL TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
ERROR: Unsupported isolation level: READ UNCOMMITTED
2,单条sql 执行时间(select /update/insert/delete)分析
现象: multi region 下的DSQL,insert/update 单条数据修改,完成时间也大概在100ms,如果在在单region 下的DSQL大概是2ms 左右。
猜测是有两个网络交互
1,Adjudicator 会到peer Adjudicator 做一次对等同步。(50ms)这里是要通知peer ajudicator 当前事务的Tcommit。全局的Tcommit 只能递增不能回退。参考( https://brooker.co.za/blog/2024/12/05/inside-dsql-writes.html Consistency 部分)是为了保证读数据的时候,用Tstart 读取数据读到的数据版本是固定的。如果row 的Tcommit 反覆横跳, 每一次读到的版本会不一致。
2,写Journal ,要确保写到peer 的Journal 里面, 这里做一次对等同步。(50ms) 这里是为了保证强一致性, A region 写入的数据B 上面马上能读出来。
总结:
目前DSQL 使用的场景是目前是需要高弹性服务的用户,不用担心业务突增再来的数据库架构变化。相对于阿里云Global Database Network(GDN),Aurora Global Database(AGD), 有优势的场景:整个事务结束的时候才去处理冲突,跨region 交互相对少。对于GDN/AGD 是在事务过程当中就要每条sql 跨region到主集群上面去执行(但是写Region只有一个也没有跨Region冲突一说)。
目前DSQL 的multi region 版本, 每一个事务都要走两次跨region 的协调。但是,如果一个写事务内部只有一个sql,类似GDN 或者AGD 的跨region 写入也只需要一次的跨region 访问。所以就造成如果用户不刻意控制DSQL 中事务的大小, 一个单条sql 的写事务在DSQL 执行甚至是比直接跨region 单点写入还要慢将近一倍。可能后续DSQL继续演进这里是有优化的空间的, 但是目前来看这里确实是比较大的问题。
另一个问题,用户也不是完全没有感知OCC 本身的,用户需要调整自己的业务结构,避免同时写入到同一个row 上面, 减少冲突,以便减少发生冲突之后,用户需要处理的重试流程。
另一个问题,对于使用上面来说DSQL 对标Postgre SQL 还是有很多限制的 https://docs.aws.amazon.com/zh_cn/aurora-dsql/latest/userguide/working-with-postgresql-compatibility-unsupported-features.html
最明显的负面限制,其最大事务不能超过5min,事务内更新行数不能超过3000。基本上有长事务的业务就不适合上DSQL了。
总体来说DSQL ,尝试用OCC 的方式解决跨Region 多写的问题,提供了一个新的思路,最大的亮点在其架构上面的可扩展性, 对于OCC 的实现和考量还有待演进。
Reference:
AWS re:Invent 2024 - Get started with Amazon Aurora DSQL (DAT424)
AWS re:Invent2024 Aurora 发布了啥 – DSQL 篇