Decentralized Placement of Replicated Data
本文提出一种分层的数据放置策略DPRD。DPRD主要应用于分布式存储系统中,目前DPRD应用于Zeppelin中。DPRD策略的想法脱胎于CRUSH算法,吸取了CRUSH算法中最显著的故障域分离的特性,同时对扩容和缩容场景做出了效果显著的优化。
CRUSH简介
CRUSH 是应用于CEPH的数据分布算法。它是一个分层的,区分故障域的分布式算法。在CRUSH算法中,对于不同的物理设备统一抽象成了bucket,每个结点都是一个bucket,其对应的物理结构各不相同。例如下图中的root,row(机架), cabinet(机柜), disk都是bucket的一种。
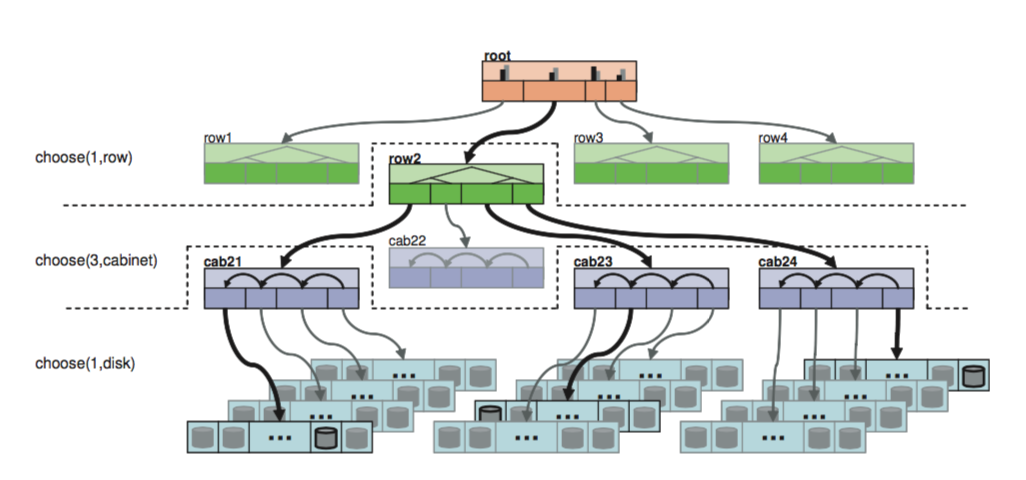
以下是对应的CRUSH算法分层部分的介绍,
- 从root bucket开始, 对应Rule take(root)。
- 在下一层选择一个row 对应Rule select(1, row)。这一层选出的是row2。
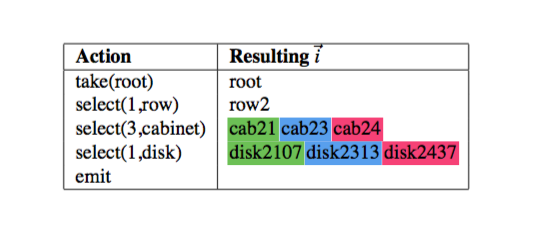
- 下一层将上一层的输出当作这一层的输入,遵循Rule select(3, cabinet), row2中选三个cabinet。最终的这一层输出是cab21, cab23, cab24。
- 下一层对应Rule select(1, disk)。在cab21, cab23, cab24 中分别选一个disk。最终emit输出是disk2107, disk2313, disk2437。
CRUSH如何实现Rule中的select N这个操作的呢?
对于每一个bucket,CRUSH的paper提供了几种不同的选择策略(Uniform, List, Tree, Straw)。如果有兴趣的同学可以读下论文。
这里简单介绍一下他的默认策略Straw:
Straw翻译过来是抽签,每个桶会计算其每个子节点的”参数值”,然后抽取一个最大的作为选中bucket。其”参数值”为的weight * hash。由于hash计算本身的随机特性,哈希值的变化会导致本来应该移动到A节点的PG,移动到了B节点。造成了额外的移动。
CRUSH 迁移策略
CEPH 的迁移是一个非常复杂的过程,涉及到其内部许多其它的机制,这里只简要说明与CRUSH算法相关的步骤。CEPH 的迁移步骤概述如下:
-
收到map的更新信息。
-
重新计算pg对应的osd信息。
-
对比之前的pg和osd的对应关系,得知如何迁移。
例如 :
由老的map信息计算得知 pg 101 对应的osd[1,2,3], 新的map信息计算得知pg 101 对应osd[1,2,4], 所以迁移方向应该是从osd3到osd4
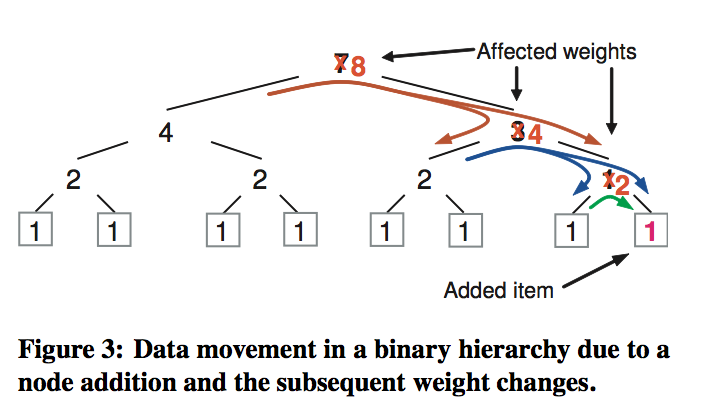
上图是CRUSH论文中提到的数据迁移现象。由于新bucket的加入,新加入节点的上层bucket权重都会改变,在做select N操作的时候,由于hash值的存在,同样权重的情况下选择到了其它的分支,这样就带来了额外的迁移。如图所示,流向新添加节点的pg是必要的移动,流向其他节点的pg是额外的迁移。
以上就是CRUSH的数据迁移策略。
Is CRUSH Perfect? Em……NO!
这部分主要提出CRUSH的两个问题,引出DPRD策略。
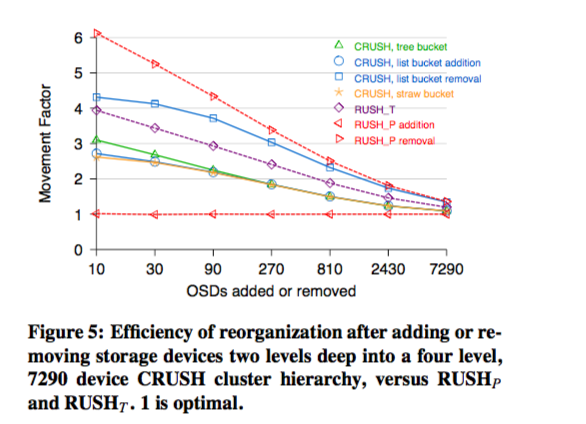
1, CRUSH 默认使用的straw bucket 会造成2到3倍于理论迁移率的移动。
2, 对于pg分布是否平衡文中没有详细的讨论。
在调研阶段对CRUSH进行了测试:
4(rack) * 10(host) * 10(node) 拓扑下 1024 * 3 副本
对于每个结点分配的pg比较少的情况,分布不均匀的现象比较明显。
2 * 10 * 2 拓扑下 1024 * 3 副本
对于每个结点分配pg比较多的情况下,分布不均匀的现象会有一定的缓解, 但是依旧离理论值很远。
具体测试数据位于测试数据中PG分布平衡性测试部分。
DPRD来了!
DPRD Target:
(在分层拓扑,故障域分离情形下)
1, 副本的移动率应该尽可能的贴近理论值
2, 副本的分布应该尽可能的贴近均匀分布
Service:
1, 副本分布的初始化过程
2, 扩容时副本的重新分布
3, 缩容时副本的重新分布
DPRD 策略
pg 和osd 是CEPH 中的概念, 对应到Zeppelin中分别为partition 和node
定义:
Factor:partition / weight
代表单位weight上所分布的partition数量。这个数量来衡量bucket负担是否过于重或者过于轻。partition倾向于在同一层中选择负担比较轻的bucket。
Base Factor: 1/ weight
partition 为1 的情况。代表移动一个partition对于Factor的影响。
Average Factor:sum of partition / sum of weight
平均的Factor参数,扩容或缩容过程中,衡量bucket是否均衡的参数。
1, 副本分布的初始化过程
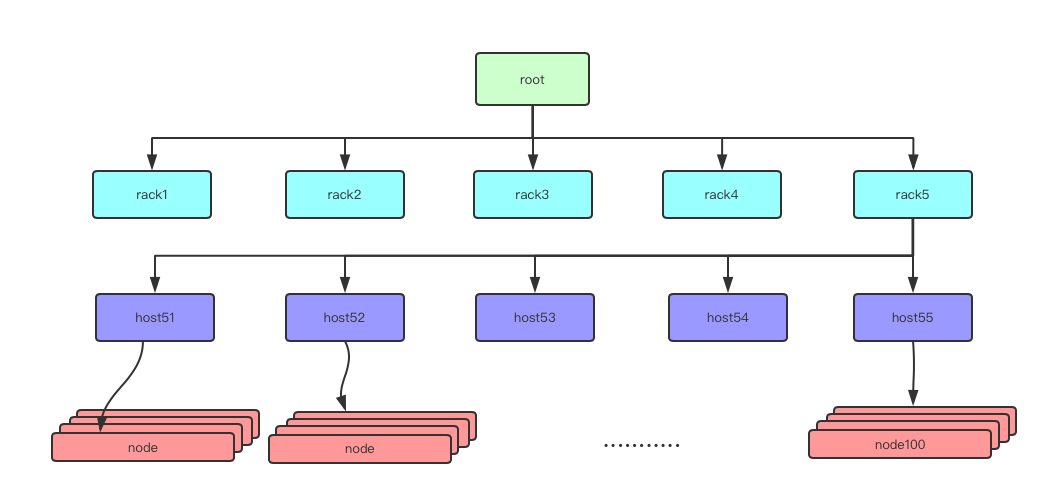
DPRD策略借鉴了CRUSH中的分层结构,从上层到下层遵循Rule依次进行partition选择。但是,对于Select N策略,DPRD跟CRUSH有很大的区别。Select N策略中,parent bucket计算子节点当前的“参数”值,然后选择前N个子节点作为这次select N的输出。所谓的参数值,在DPRD策略中是Factor(partition/weight) 代表了每个子节点的重量负担,每一次的partition选择都应该选择当前负担小的N个子节点。这样,每一次partition都会放置到本层相对于轻的bucket中,以此来保证这一层的bucket都不会过重或者过轻。
具体的数据见 测试数据Partition初始化。
2, 扩容时副本的重新分布
在添加bucket的时候会造成“不均衡”。
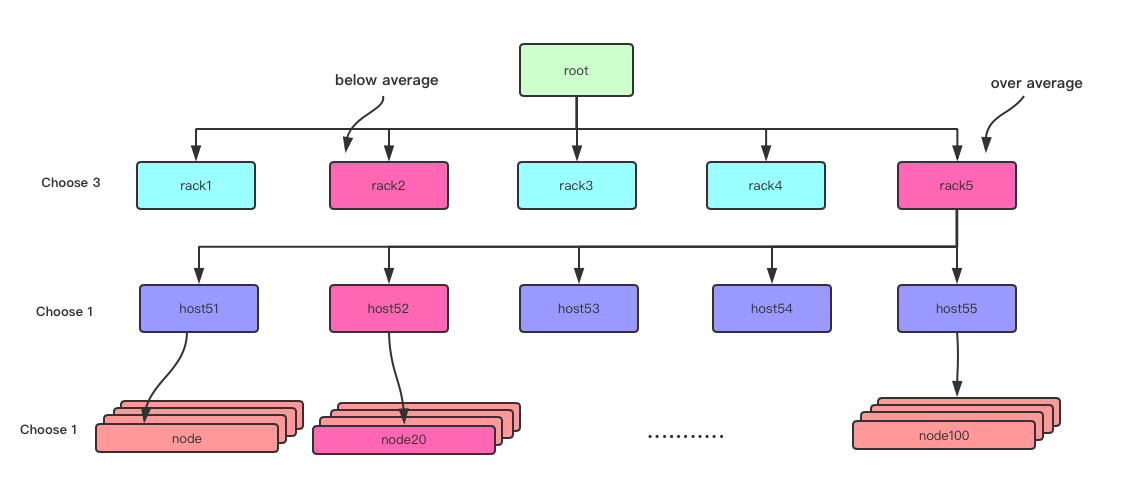
在rack2下面添加bucket会导致rack层 weight增加,以至于average factor变小。最终进行迁移之前,rack5由于本身的Factor值没变,average factor变小,rack5有可能高于average factor“很多”。rack2 由于Factor变小幅度更大,有可能低于average factor“很多”。 这样,由于新添加的bucket会有可能造成本层的不平衡(rack5超出average factor,rack2低于acerage factor)。下面定义DPRD中的“不平衡”概念,以及DPRD是如何实现平衡的。
定义“不均衡”
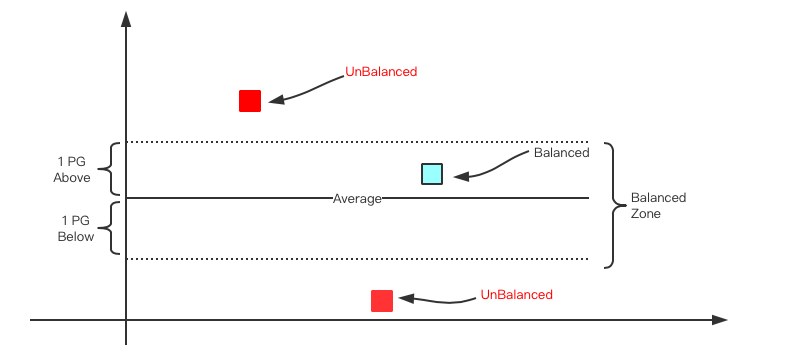
所谓不均衡是bucket的Factor超出average factor太多或者小于average factor太多
超出均值情况: factor - average_factor > base_factor
低于均值情况: average_factor - factor > base_factor
如下图所示, 每一层经过均衡的过程之后,parent bucket的所有的children bucket都应该落在平衡区域内。
整体上来看, DPRD策略是从上层到下层做均衡,确保每一层都是均衡的。从root层开始,其children为rack,由于rack5高于average factor, rack2 低于average factor。DPRD策略会在rack5 子树的node中选择一个partition移动到rack2 中。直到rack层的每一个bucket都均衡之后,DPRD策略会再均衡下一层(host层),直到遍历整棵树。
问题来了,我们应该选择rack5种哪一个node中的哪一个partition呢?
DPRD选择策略
Target:从rack5 子树选出一个bucket的partition 移动到rack2中
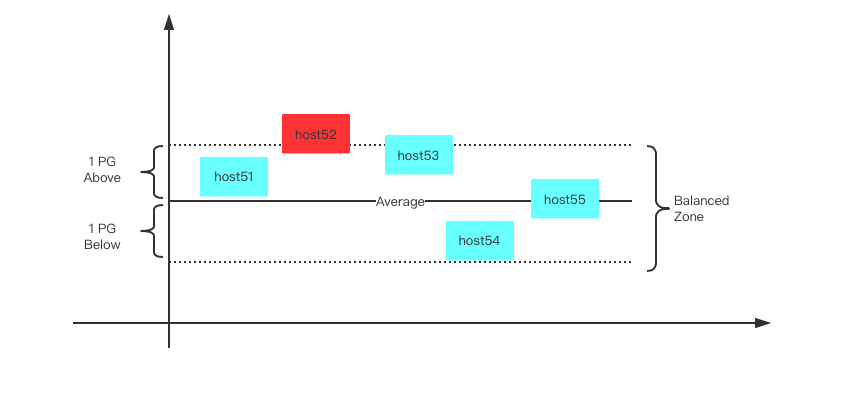
Step1: 从rack5 children中选择出正向偏离average factor最远的host(host52)如下图所示。
Step2: 遵循step1的原则向下递归选择bucket,直到选择一个node bucket。
Step3: 在node bucket中选择一个rack2 中没有的partition 移动到rack2。
如果没有能够在Step3中选择出一个partition那么重新回到Step1 选择 host53,继续流程。
至此,上文中说明了DPRD扩容的partition迁移策略。具体的测试结果位于测试数据中扩容测试部分。
3, 缩容时副本的重新分布
最直观的实现就是把要去除的bucket里边的partition从拓扑里面全都移除掉,包括该partition在其他node上的副本。然后再从root进行副本的初始化过程。这样会带来3倍于理论移动率的迁移。
DPRD 的实现:
只去除需要删除的bucket中的partition副本,同时为保障choose_n的故障域策略,需要在choose_n的那一层,在从没有该partition副本的bucket中选择出一个新的副本放置位置。
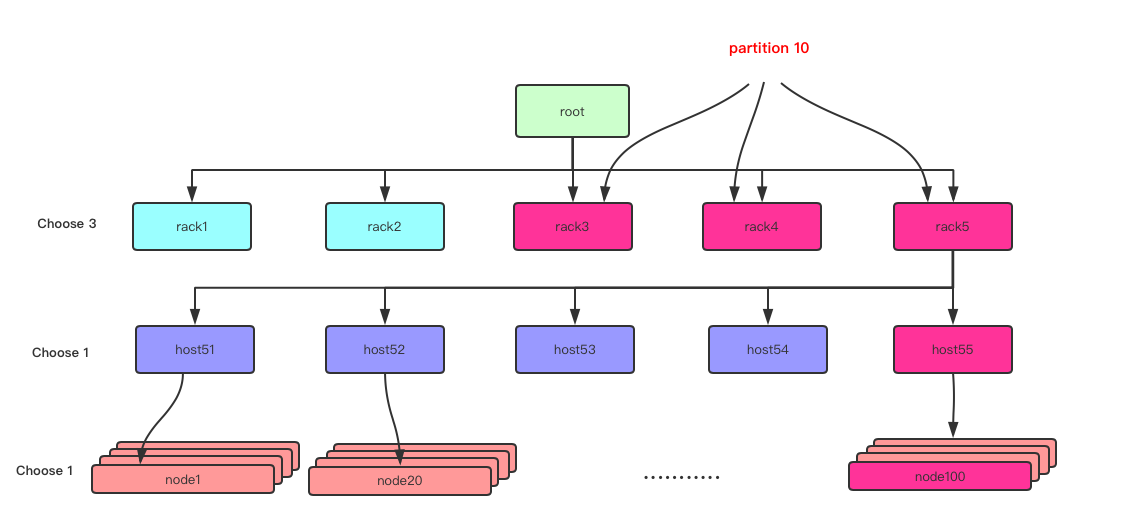
Step 1.记录partition 10 在choose_n 层的位置(rack3, rack4, rack5)
Step 2. 移除要删除的 bucket (bucket100)
Step 3. 在choose_n 层选择一个目前没有partition 10的bucket(rack1 或者rack2)
Step 4. 从选出的bucket 开始做副本的初始化过程。
至此,上文中介绍了DPRD缩容的partition迁移策略。具体的测试结果位于测试数据中缩容测试部分。
总结:
本文提出了一种DPRD的数据分布策略,在保证故障域分离的情况下,尽量保证数据的均匀分布。同时本文讨论了在扩容和缩容时,DPRD如何保证尽量贴近理论极限的数据迁移。